 |
|
Oracle sorted hash cluster tips
Oracle Database Tips by Donald Burleson |
If your database has a high volume of
transactions that join two tables with a subordinate index range
scan, grouping the rows together with sorted hash clusters can have a profound impact on
reducing I/O.
For example, clustering all orders for a customer together on the
same data block allows the query "show me all orders for this
customer" to be retrieved in a single fetch.
See here for more details on using hashing to group data rows
onto related data blocks. The
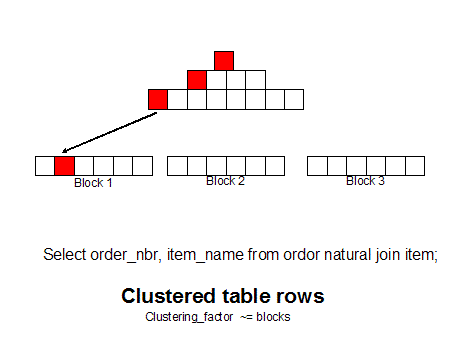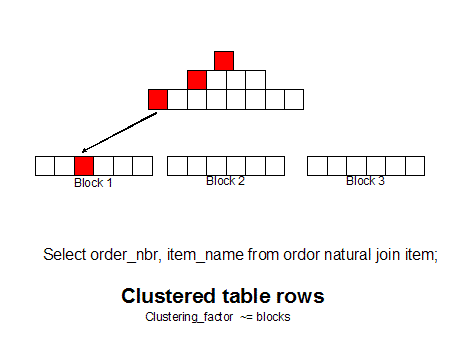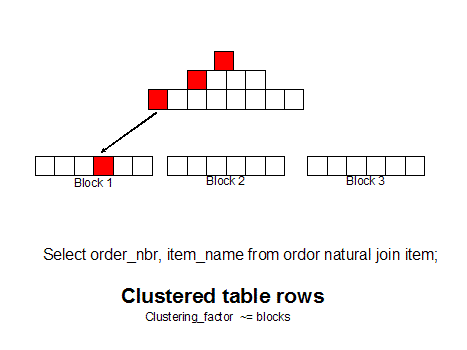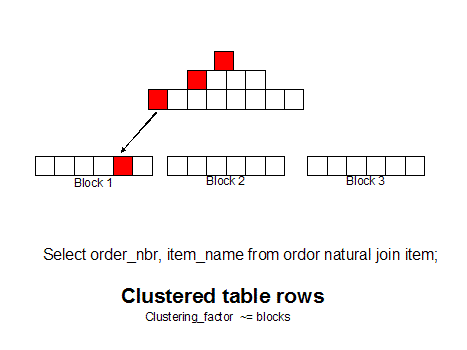
clustering_factor metric shows how in-sync the rows are.

With row re-sequencing, adjacent rows are
together, greatly reducing I/O:

Figure 15.8:
This column
has a low clustering factor, small rows and large blocks.
For
queries that access common rows with a table (e.g. get all items in
order 123), unordered tables can experience huge I/O as the index
retrieves a separate data block for each row requested.

If we
group like rows together (as measured by the clustering_factor in
dba_indexes) we can get all of the row with a single block read
because the rows are together. You can use 10g hash cluster
tables, single table clusters, or manual row re-sequencing (CTAS
with ORDER BY) to achieve this goal:
Oracle has had several methods for
re-sequencing table rows together, but the best is the Oracle sorted hash cluster:
-
Single table cluster tables - This
uses an overflow area
-
CTAS with order by clause - The DBA
manually reorgs the table, reordering the table rows together on
adjacent data blocks.
-
Sorted hash clusters - The new 10g
way of assigning rows to adjacent data blocks.
The latest method, the Oracle sorted hash
cluster, is a great way to ensure row adjacency. Let's take a
closer look at sorted hash clusters.
Creating a sorted hash
cluster
The Oracle 10g documentation notes "In a
sorted
hash cluster,
the rows corresponding to each value of the hash function are sorted
on a specified set of columns in ascending order, which can improve
response time during subsequent operations on the clustered data.".
In Oracle10g and beyond, a sorted hash cluster allows you to define a hash sort
key and have Oracle place the row on the target
create cluster
orders_cluster
(
ordor_nbr number,
ordor_date date,
customer_nbr number sort
)
hashkeys 10000
hash is ora_hash(customer_nbr)
size 256;
create table ordor
(
ordor_nbr number,
ordor_date date,
customer_nbr number sort
)
cluster
ordor_cluster
(
customer_nbr, transdate
);
As we see, the Oracle sorted hash clusters are a great
way to reduce I/O stress on Oracle databases where related rows are
grouped together physically on the data block.
 |
For a complete treatment of using Oracle
sorted hash clusters, see my book.
"Oracle
Tuning: The Definitive Reference".
You can buy it direct from the publisher for 30%-off and get
instant access to the code depot of Oracle tuning scripts: |
Sorted hash clusters references:
Oracle has some great advice for
tuning-down "db file sequential
read" waits by taking read-only tables and reorganization the table in index row-order:
- If Index Range scans are
involved, more blocks than
necessary could be being visited
if the index is unselective: by
forcing or enabling the use of
a more selective index, we can
access the same table data by
visiting fewer index blocks (and
doing fewer physical I/Os).
- If the index being used has
a large Clustering Factor (in dba_indexes), then
more table data blocks have to
be visited in order to get the
rows in each Index block:
My related pages on sorted hash clusters:
|


