Experienced Oracle DBAs know that I/O is
often the single greatest component of response time and regularly
work to reduce I/O. Disk I/O is expensive because when Oracle
retrieves a block from a data file on disk, the reading process must
wait for the physical I/O operation to complete.
Disk operations are
about 10,000 times slower than a row's access in the data buffers (in
Oracle, about 100x faster due to latch overhead).
Consequently, anything you can do to minimize I/O or reduce
bottlenecks caused by contention for files on disk-greatly improves
the performance of any Oracle database.

For
queries that access common rows with a table (e.g. get all items in
order 123), unordered tables can experience huge I/O as the index
retrieves a separate data block for each row requested.

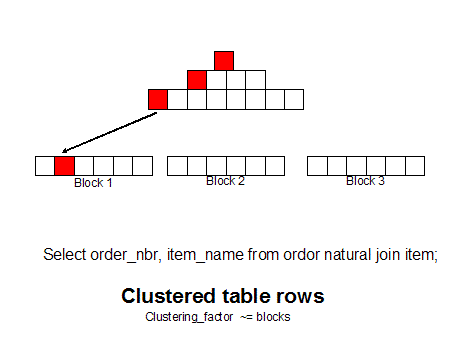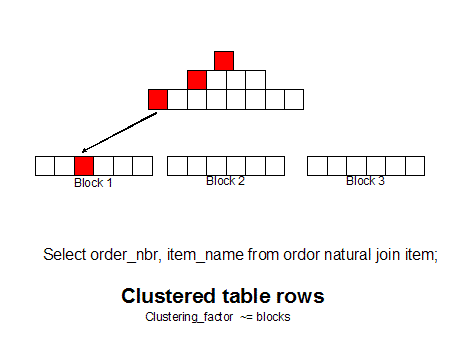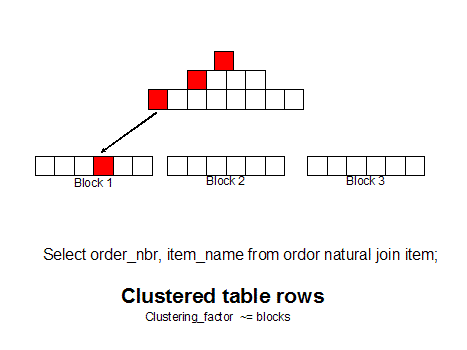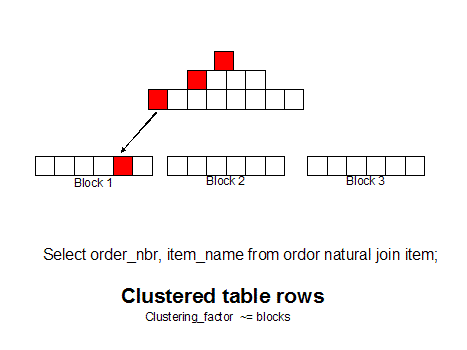
If we
group like rows together (as measured by the clustering_factor in
dba_indexes) we can get all of the row with a single block read
because the rows are together. You can use 10g hash cluster
tables, single table clusters, or manual row re-sequencing (CTAS
with ORDER BY) to achieve this goal:
In
high-volume online transaction processing (OLTP) environments, in which
data is accessed via a primary index, re-sequencing table rows so that
contiguous blocks follow the same order as their primary index can
actually reduce physical I/O and improve response time during
index-driven table queries. This technique is useful only when the
application selects multiple rows, when using index range scans, or if
the application issues multiple requests for consecutive keys.
Databases with random primary-key unique accesses won't benefit from
row re-sequencing.
Let's
explore how this works. Consider a SQL query that retrieves 100 rows
using an index:
select
salary
from
employee
where
last_name like 'B%';
This
query will traverse the last_name_index, selecting each row to
obtain the rows. This query will have at least 100 physical disk reads
because the employee rows reside on different data blocks.
The
benefits of row re-sequencing cannot be underestimated. In large
active tables with a large number of index scans, row re-sequencing
can triple the performance of queries.
Lets
take look at the most common methods for row-re-sequencing for table
that are always accessed via index range scans.
Oracle Index Cluster Tables
Unlike
the hash cluster where the symbolic key is hashed to the data block
address, an index cluster uses an index to maintain row sequence.
A table
cluster is a group of tables that share the same data blocks, since
they share common columns and are often used together. When you create
cluster tables, Oracle physically stores all rows for each table in
the same data blocks. The cluster key value is the value of the
cluster key columns for a particular row.
Index
cluster tables can be either multi-table or single-table. Lets take
a look at each method.
Multi-table Index Cluster Tables
In a
multi-table index cluster, related table rows are grouped together to
reduce disk I/O.
 |
For example, assume that you have
a customer and orders table and 95% of the access is to select all
orders for a particular customer. Oracle
will have to perform an I/O to fetch the customer row and then
multiple I/Os to fetch each order for the customer. |
Consider
this SQL where we fetch all orders for a customer:
select
customer_name,
order_date
from
customer
natural join
orders
where
cust_key = IBM;
If this
customer has eight orders, each on a different data block, we must
perform nine block fetches to return the query rows. Even if these
blocks are already cached in the data buffers, we still have at least
nine consistent gets:

If we re-define the table as a index
cluster table, Oracle will physically store the orders rows on the
same data block as the parent customer row, thereby reducing I/O by a
factor of eight:

Remember, index clusters will only
result in a reduction of I/O when the vast majority of data access is
via the cluster index. Any row access via another index will still
result in randomized block fetches.
Single-table Index
Cluster Tables
A single-table index cluster table is
a method whereby Oracle guarantees row sequence where
clustering_factor in dba_indexes always approximates
blocks in dba_tables.

Scans via an index range scan will
always fetch as many rows as possible in a single I/O, depending on
your block size and average row length. Many shops that employ
single-table index cluster tables use a db_32k_cache_size to
ensure that they can fetch an index range scan in a single I/O.

To do this, Oracle must have an overflow area
where new rows are placed if there is not room on the target block.
Monitoring the overflow becomes an important task and the DBA may have
to periodically reorganize the single-table index cluster table to
ensure that all row orders are maintained. The DBA will lower the
value of PCTFREE for the table to reserve space for new rows, but
excessive row write to the overflow area will cause the
clustering_factor to rise above the value for blocks in
dba_tables.


