Important 2015 update:
The rules for identification of candidates for index
rebuilding are changing. Please see my
updated notes on index rebuilding.
Row re-sequencing is not
for every table. See
my notes to understand the concepts behind table row
re-sequencing and how to tell if re-sequencing the rows
in your table might improve your SQL execution speed.
The clustering_factor
measures how synchronized an index is with the data in a
table. A table with a high clustering factor is
out-of-sequence with the rows and large index range
scans will consume lots of I/O. Conversely, an
index with a low clustering_factor is closely
aligned with the table and related rows reside together
of each data block, making indexes very desirable for
optimal access.
You can improve the
clustering_factor for an index by using
dbms_redefinition to move the table to an IOT.
This will re-sequence the rows into the same order as
the index.
Rules for
Oracle indexing
To understand how Oracle chooses the execution plan for
a query, you need to first learn how the SQL
optimizer decides whether or not to use an index.
Oracle provides a
column called clustering_factor in the
dba_indexes view that provides information on how
the table rows are synchronized with the index. The
table rows are synchronized with the index when the
clustering factor is close to the number of data blocks
and the column value is not row-ordered when the
clustering_factor approaches the number of rows in
the table.
For queries that access
common rows with a table (e.g. get all items in order
123), unordered tables can experience huge I/O as the
index retrieves a separate data block for each row
requested.

If we group like rows
together (as measured by the clustering_factor in
dba_indexes) we can get all of the row with a single
block read because the rows are together.
Note: As we see
grouping related rows together can make a huge reduction
in disk I/O, and Oracle has embraced this row sequencing
idea in 10g and beyond with the
sorted hash cluster, a fully supported way to ensure
that related rows always reside together on the same
data block.
Today we have choices for
row sequencing. We
can
even group related rows from several tables together
with multi-table
hash
clusters, or we can use single table clusters, or
manual row re-sequencing (CTAS with ORDER BY) to achieve
this goal:
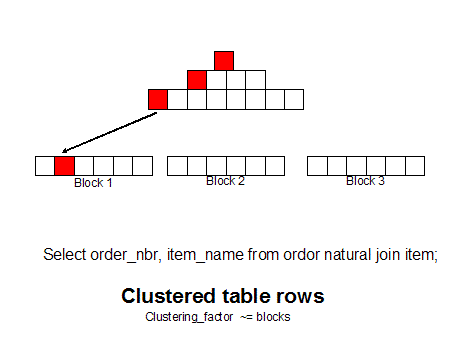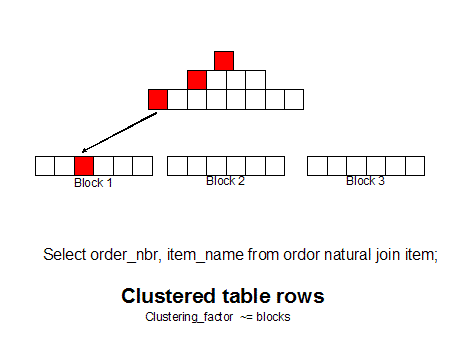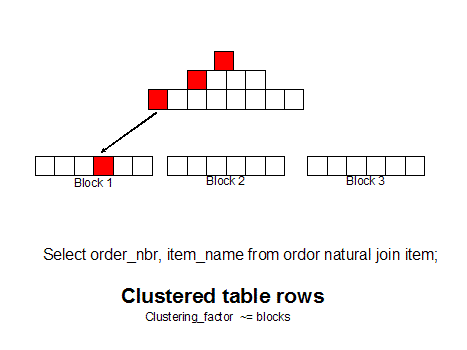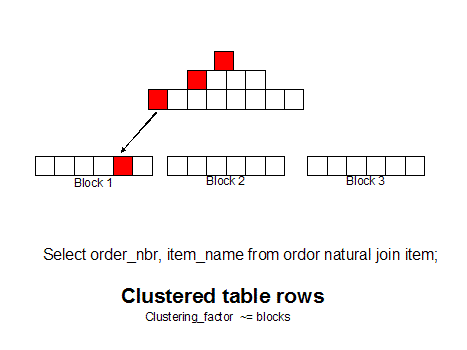
To illustrate, consider this query that filters the
result set using a column value:
select
customer_name
from
customer
where
ustomer_state = ‘New Mexico';
Here, the decision to use an index vs. a full-table scan
is at least partially determined by the percentage of
customers in New Mexico. An index scan is faster for
this query if the percentage of customers in New Mexico
is small and the values are clustered on the data
blocks.
Why, then, would a CBO choose to perform a full-table
scan when only a small number of rows are retrieved?
Perhaps it is because the CBO is considering the
clustering of column values within the table.
Four factors work together to help the CBO decide
whether to use an index or a full-table scan: the
selectivity of a column value, the db_block_size,
the avg_row_len, and the cardinality. An index
scan is usually faster if a data column has high
selectivity and a low clustering_factor.
| |
 |
| This column has small rows,
large blocks, and a low clustering factor.
In the real-world, many Oracle database use the
same index for the vast majority of queries.
If these queries always to an index range scan
(e.g. select all orders for a customer), them
row re-sequencing for a better
clustering_factor can greatly reduce Oracle
overhead:
|

Oracle provides several storage mechanisms to fetch a
customer row and all related orders with just a few row
touches:
- Sorted hash clusters - New in 10g, a
great way to sequence rows for super-fast SQL
- Multi-table hash cluster tables - This will
cluster the customer rows with the order rows, often
on a single data block.
- Periodic reorgs in primary index order -
You can use the dbms_redefinition utility to
periodically re-sequence rows into index order.
To maintain row order, the DBA will periodically
re-sequence table rows (or use a
single-table,
or multi-table cluster) in
cases where a majority of the SQL references a
column with a high clustering_factor, a large
db_block_size, and a small avg_row_len. This
removes the full-table scan, places all adjacent rows in
the same data block, and makes the query up to thirty
times faster.
On the other hand, as the clustering_factor nears
the number of rows in the table, the rows fall out of
sync with the index. This high clustering_factor,
where the value is close to the number of rows in the
table (num_rows), indicates that the rows are out
of sequence with the index and an additional I/O may be
required for index range scans.
Even when a column has high selectivity, a high
clustering_factor, and small avg_row_len,
there is still indication that column values are
randomly distributed in the table, and an additional I/O
will be required to obtain the rows. An index range scan
would cause a huge amount of unnecessary I/O as shown in
below, thus making a full-table scan more
efficient.
|
 |
| This column has large rows,
small blocks, and a high clustering factor. |
In sum, the CBOs decision to perform a full-table vs.
an index range scan is influenced by the
clustering_factor, db_block_size, and
avg_row_len. It is important to understand how the
CBO uses these statistics to determine the fastest way
to deliver the desired rows.
For more information on
table clustering and row-re-sequencing techniques (and
scripts), please see my latest book "Oracle
Tuning: The Definitive Reference".
 |
|
Get the Complete
Oracle SQL Tuning Information
The landmark book
"Advanced Oracle
SQL Tuning The Definitive Reference" is
filled with valuable information on Oracle SQL Tuning.
This book includes scripts and tools to hypercharge Oracle 11g
performance and you can
buy it
for 30% off directly from the publisher.
|


