| |
 |
|
Oracle index rebuilding:
Indexes to rebuild script
Oracle Tips by Burleson
|
Executive Summary on index rebuilding
While it may be rare to rebuild an Oracle index
for performance reasons, there are some databases that will get
a measurable performance boost from rebuilding indexes.
These workloads have these characteristics:
-
High index
fragmentation: The SQL workload has lots of
table DML causing lots of deleted leaf blocks.
-
High index scan
access plans: The SQL workload is rich with
index scans (index fast-full scans and index range scans)
The rules for identification of candidates for index coalescing/rebuilding
depend on your specific index state. See MOSC notes
989186.1, 122008.1, 989093.1 for Oracle's suggestions on when to
coalesce/rebuild indexes. Also see my
updated notes on index coalesce/rebuilding and note that this DBA has demonstrated the
characteristics indexes that benefits from
scheduled oracle index rebuilding.
Note:
Per bug
3661285, the Oracle 11g segment advisor now detects sparse
indexes and automatically flags them for rebuilding.
How rare are "bad" indexes?
You cannot generalize to say that index
rebuilding for performance is rare, or even medium rare, it
depends on many factors, most importantly the characteristics of
the application.
-
In scientific applications (clinical, laboratory) where
large datasets are added and removed, the need to rebuild
indexes is "common".
-
Conversely, in system that never update or delete rows,
index rebuilding rarely improves performance.
-
In systems that do batch DML jobs, index rebuilding "often"
improves SQL performance.
See
Oracle MOSC note
122008.1 for the officially authorized script to detect
indexes that benefit from rebuilding. This script detects
indexes for rebuilding using these rules:
Rebuild the index when
these conditions are true:
- deleted entries represent 20% or more of the current entries.
- the index depth is more then 4 levels.
I also have more
sophisticated index rebuilding scripts in my book "Oracle
Tuning: The Definitive Reference", with a code depot of downloadable
diagnostic scripts.
Script to rebuild indexes
It is very difficult to write a script that
will identify indexes that will benefit from rebuilding because
it depends on how the indexes are used. For example,
indexes that are always accessed vis an index unique scan" will
never need rebuilding, because the "dead space" does not
interfere with the index access.
Only indexes that have a high number of
deleted leaf blocks and are accessed in these ways will benefit
from rebuilding:
-
index fast full scan
-
index full scan
-
index range scan
Getting statistically valid: proof from a volatile production system would be a
phenomenal challenge. In a large production system, it would be a massive
effort to trace LIO from specific queries to specific indexes before and after
the rebuild.
When rebuilding fragmented (indexes with
deleted leaf nodes) we will expect the space to be reduced:
col segment_name format a40
col blocks
format 999,999,999
select
segment_name,
blocks
from
dba_segments
where
segment_type = 'INDEX'
and
owner = 'xxx';
Normally, these indexes attempt to manage
themselves internally to ensure fast access to the data rows.
However, excessive activity within a table can cause Oracle
indexes to dynamically reconfigure themselves. This
reconfiguration involves three activities:
-
Index spawning At some point,
the Oracle indexes will reach the maximum capacity for the
level and the Oracle index will spawn, creating a deeper
level structure
-
Index node deletion As you may know, Oracle
index nodes are not physically deleted when table rows are
deleted, nor are the entries removed from the index. Rather,
Oracle 'logically' deletes the index entry and leaves dead
nodes in the index tree.
Indexes require rebuilding when deleted
leaf nodes appear or when the index has spawned into too many
levels of depth. While it is tempting to write a script that
rebuilds every index in the schema, bear in mind that Oracle
contains many thousands of indexes, and a complete rebuild can
be very time consuming. Hence, we need to develop a method to
identify those indexes that will get improved performance with a
rebuild. Let's look at a method for accomplishing this task.
One vexing issue with Oracle indexes is
that the information for an index rebuild must be gathered from
two sources:
ANALYZE INDEX index_name COMPUTE STATISTICS
ANALYZE INDEX index_name VALIDATE STRUCTURE
Once we gather information from these sources, we
can generate a report with everything we need to know about the
index internal structure:
# rep dist.
# deleted
blk gets
Index
keys keys
leaf rows Height per
access
-------------------- ------
----- -------- ------
-----
CUST_IDX
1 423,209
58,282 4
6
EDU_IDX_12
433 36,272
7,231 3
2
CUST_IDX
12 1,262,393
726,361 4
6
From this report, we see several important
statistics:
-
The number of deleted leaf nodes The
term 'deleted leaf node' refers to the number of index nodes
that have been logically deleted as a result of row
delete operations. Remember that Oracle leaves dead
index nodes in the index when rows are deleted. This is done
to speed up SQL deletes, since Oracle does not have to
rebalance the index tree when rows are deleted.
-
Index height The height of the
index refers to the number of levels that are spawned by the
index as a result in row inserts. When a large number of
rows are added to a table, Oracle may spawn additional
levels of an index to accommodate the new rows. Hence, an
Oracle index may have four levels, but only in those areas
of the index tree where the massive inserts have occurred.
Oracle indexes can support many millions of entries in three
levels, and any Oracle index that has four or more levels
would benefit from rebuilding.
-
Gets per index access The number
of gets per access refers to the amount of logical I/O
that is required to fetch a row with the index. As you may
know, a logical get is not necessarily a physical I/O since
much of the index may reside in the Oracle buffer cache.
The script to make the report is complex
because both the validate structure and compute
statistics commands must be executed. The following code
snippets are used to generate the report.
WARNING -
This script for experts only.
It is extremely resource intensive. DO NOT run it in an
active production environment. Only run this script during
scheduled downtime.
Oracle OTN
published this Korn shell script to identify highly fragmented
indexes, targeting indexes that are 4 levels or more, or indexes
with a high number of deleted leaf blocks:
#!/bin/ksh
export ORACLE_HOME=/app/d006/01/product/ora/11204/bin
export ORACLE_SID=D006A
export FPATH=/tmp
$ORACLE_HOME/sqlplus -s User1/pwd << EOF
set echo off
set termout off
set verify
off
set trimspool on
set
feedback off
set heading off
set lines 300
set pages 0
set serverout on
spool
analyze_User1_indexes.tmp
select 'exec
DBMS_STATS.UNLOCK_TABLE_STATS ('''|| user ||''','''|| table_name
||''');' from user_tables order by table_name asc;
begin
for x
in ( select index_name from user_indexes where index_type =
'NORMAL')
loop
dbms_output.put_line('ANALYZE INDEX ' || x.index_name || '
COMPUTE STATISTICS;');
dbms_output.put_line('ANALYZE INDEX ' || x.index_name || '
VALIDATE STRUCTURE;');
dbms_output.put_line('select name, height, lf_rows, del_lf_rows,
round((del_lf_rows/lf_rows)*100,2) as ratio from index_stats
where (lf_rows > 100 and del_lf_rows
> 0)
and (height > 3 or ((del_lf_rows/lf_rows)*100)
> 20);');
end loop;
end;
/
select 'exec DBMS_STATS.LOCK_TABLE_STATS
('''|| user ||''','''|| table_name ||''');' from user_tables
order by table_name asc;
spool off
column name format a40
spool FPATH/analyze_User1_index_report.txt
PROMPT NAME | HEIGHT | LF_ROWS |
DEL_LF_ROWS | RATIO (del_lf_rows/lf_rows) %
@@$FPATH/analyze_User1_indexes.tmp
spool off
EOF
exit
There are many
compelling reasons to manage indexes within Oracle. In an OLTP
system, index space is often greater than the space allocated for
tables, and fast row data access is critical for sub-second
response time. As we may know, Oracle offers a wealth of index
structures:
-
B-tree
indexes: .This
is the standard tree index that Oracle has been using since the earliest
releases.
-
Bitmap
indexes:
Bitmap indexes are used where an index column has a relatively small number of
distinct values (low cardinality). These are super-fast for read-only
databases, but are not suitable for systems with frequent updates
-
Bitmap
join indexes:
This is an index structure whereby data columns from other tables appear in a
multi-column index of a junction table. This is the only create index syntax
to employ a SQL-like from clause and where clause.
create bitmap
index
part_suppliers_state
on
inventory(
parts.part_type, supplier.state )
from
inventory i,
parts p,
supplier s
where
i.part_id=p.part_id
and
i.supplier_id=s.supplier_id;
In
addition to these index structures we also see interesting use of indexes at
runtime. Here is a sample of index-based access plans:
-
Nested
loop joins:
This row access method scans an index to collect a series of ROWID?s.
-
Index
fast-full-scans: This is a: multi-block read access where the index blocks are accessed via
a: db file scattered read to load index blocks into the buffers. Please note
that this method does not read the index nodes.
-
Star
joins: The star
index has changed in structure several times, originally being a
single-concatenated index and then changing to a bitmap index implementation.
STAR indexes are super-fast when joining large read-only data warehouse
tables.
-
Index
combine access:
This is an example of the use of the index_combine hint. This
execution plan combines bitmap indexes to quickly resolve a low-cardinality
Boolean expression:
select /*+ index_combine(emp, dept_bit, job_bit) */
ename,
job,
deptno,
mgr
from
emp
where
job = 'SALESMAN'
and
deptno = 30
;
Here is the execution plan that shows the index
combine process:
OPERATION
----------------------------------------------------------------------
OPTIONS OBJECT_NAME POSITION
------------------------------ ---------------------------- ----------
SELECT STATEMENT
2
TABLE ACCESS
BY INDEX ROWID EMP 1
BITMAP CONVERSION
TO ROWIDS 1
BITMAP AND
BITMAP INDEX
SINGLE VALUE DEPT_BIT 1
BITMAP INDEX
SINGLE VALUE JOB_BIT 2
While
the internals of Oracle indexing are very complex and open to debate, there are
some things that you can do to explore the internal structures of your indexes.
Let?s take a closer look at the method that I use to reveal index structures.
Oracle index rebuilding scripts
Ken Adkins, a respected Oracle author, notes that it is
often difficult to pinpoint the exact reason that indexes
benefit from a rebuild:
"The DBAs were pulling out their hair
until they noticed that the size of the indexes were too
large for the amount of data in the tables, and remembered
this old: myth?, and decided to try rebuilding the indexes
on these tables.
The DELETE with the multiple NOT EXISTS went from running for 2 hours to delete 30,000 records, to deleting over 100,000 records in minutes. Simply by rebuilding the indexes?."
An Oracle ACE notes this script to rebuild his
indexes. "I eventually wrote a simple query that generates
a list of candidates for index rebuilds, and the commands
necessary to rebuild the indexes once the tables reached a point
where it was necessary. The query reads a table we built called TABLE_MODIFICATIONS that we loaded each night from
DBA_TAB_MODIFICATIONS before we ran statistics. Monitoring must
be turned on to use the DBA_TAB_MODIFICATIONS table."
select
'exec analyzedb.reorg_a_table4('||''||rtrim(t.table_owner)||''||','||''||
rtrim(t.table_name)||''||');',
t.table_owner||'.'||t.table_name name,
a.num_rows,
sum(t.inserts) ins,
sum(t.updates) upd,
sum(t.deletes) del,
sum(t.updates)+sum(t.inserts)+sum(t.deletes) tot_chgs,
to_char((sum(t.deletes)/(decode(a.num_rows,0,1,a.num_rows)))*100.0,?999999.99′)
per_del,
round(((sum(t.updates)+sum(t.inserts)+sum(t.deletes))/(decode(a.num_rows,0,1,a.num_rows))
*100.0),2) per_chg
from analyzedb.table_modifications t,
all_tables a
where t.timestamp >= to_date('&from_date','dd-mon-yyyy') and
t.table_owner = a.owner and t.table_owner not in ('SYS','SYSTEM')
and
t.table_name=a.table_name
having (sum(t.deletes)/(decode(a.num_rows,0,1,a.num_rows)))*100.0
>=5
group by t.table_owner, t.table_name, a.num_rows
order by num_rows desc, t.table_owner, t.table_name;
The Debate Continues
Today, a
battle is raging between the: academics? who do not believe that indexes should
be rebuilt without expensive studies, and the: pragmatists? who rebuild indexes
on a schedule because their end-users report faster response times.
To date,
none of the world's Oracle experts has determined a reliable rule for index
rebuilding, and no expert has proven that index rebuilds "rarely" help.
-
Academic
approach - Many
Oracle experts claim that indexes rarely benefit from rebuilding, yet none has
ever provided empirical evidence that this is the case, or what logical
I/O conditions arise in those: rare? cases where indexes benefit from
rebuilding.
-
Pragmatic approach: Many IT managers force their Oracle DBAs to periodically rebuild indexes
because the end-user community reports faster response times following the rebuild. The pragmatists are not interested in: proving? anything, they are
just happy that the end-users are happy. Even if index rebuilding were to be
proven as a useless activity, the Placebo Effect on the end-users is enough to
justify the task.
It is
clear that all 70 of the index metrics interact together in a predictable way.
Some scientist should be able to take this data and reverse-engineer the
internal rules for index rebuilding, if any actually exist. For now, the most
any Oracle professional can do is to explore their indexes and learn how the
software manages b-tree structures.
When can we "prove" a benefit from an index
rebuild? Here, Robin Schumacher
proves that an index that is rebuilt in a larger tablespace will
contain more index entries be block, and have a flatter structure:
"As you can see, the amount of logical reads has
been reduced in half simply by using the new 16K tablespace and accompanying
16K data cache."
In an OracleWorld 2003 presentation titled: Oracle Database 10g: The Self-Managing
Database by Sushil Kumar of Oracle Corporation, Kumar
states that the new Automatic Maintenance Tasks (AMT) Oracle10g
feature will "automatically detect and re-build sub-optimal
indexes. However, the 10g segment advisor only recommends index
rebuilding from a space reclamation perspective, not for performance.
This
Kim Floss article shows the Oracle 10g segment advisor recommending a
rebuild of an index:
'The page lists all the segments
(table, index, and so on) that constitute the object under review. The
default view ("View Segments Recommended to Shrink") lists any segments that
have free space you can reclaim.'
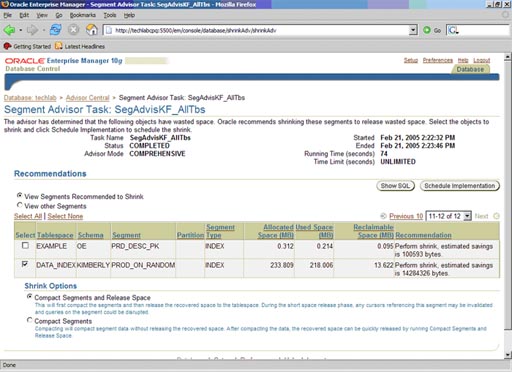
Oracle index rebuild advisor (Source: Oracle Corporation)
Inside Oracle b-tree
indexes
There
are many myths and legends surrounding the use of Oracle indexes, especially the
ongoing passionate debate about rebuilding of indexes for improving
performance. Some experts claim that periodic rebuilding of Oracle b-tree
indexes greatly improves space usage and access speed, while other experts
maintain that Oracle indexes should: rarely be rebuilt. Interestingly, Oracle
reports that the new Oracle10g Automatic Maintenance Tasks (AMT) will
automatically detect indexes that are in need of re-building. Here are the
pros
and cons of this highly emotional issue:
-
Arguments for Index Rebuilding: Many Oracle shops schedule periodic index rebuilding, and report measurable
speed improvements after they rebuild their Oracle b-tree indexes. In an
OracleWorld 2003 presentation titled
Oracle Database 10 g: The Self-Managing Database by Sushil Kumar of Oracle
Corporation, Kumar states that the Automatic Maintenance Tasks (AMT) Oracle10g
feature will automatically detect and rebuild sub-optimal indexes. : AWR
provides the Oracle Database 10g a very good 'knowledge' of how it is being
used. By analyzing the information stored in AWR, the database can identify
the need of performing routine maintenance tasks, such as optimizer statistics
refresh, rebuilding indexes, etc. The Automated Maintenance Tasks
infrastructure enables the Oracle Database to automatically perform those
operations.?
-
Arguments against Index Rebuilding: Some Oracle in-house experts maintain that Oracle indexes are
super-efficient at space re-use and access speed and that a b-tree index
rarely needs rebuilding. They claim that a reduction in Logical I/O (LIO)
should be measurable, and if there were any benefit to index rebuilding,
someone would have come up with: provable? rules.
So who
is right? I suspect that they both are correct. There is a huge body of
evidence that index rebuilding makes the end-users report faster response time,
and I have to wonder if this is only a Placebo Effect, with no scientific
basis. Some experts suspect a Placebo Effect may be at work here, and the
end-users, knowing that they have new index trees, report a performance gain
when none exists.
Because
of their
extreme flexibility, Oracle b-tree indexes are quite complex, and to really
gather scientific evidence we must examine all of the index metrics. Getting a
meaningful measure of the benefit of an index rebuild in a production
environment is very difficult because the system is under heavy load and usage
patterns change constantly. Plus, many IT managers require periodic index
re-building because it is a low-risk job and it curries favor from the end-user
community.
Where are the index
details?
Most
Oracle professionals are aware of the dba_indexes view, which is populated
with index statistics when indexes are analyzed. The dba_indexes view
contains a great deal of important information for the SQL optimizer, but there
is still more to see. Oracle provides an analyze index xxx validate
structure command that provides additional statistics into a temporary
tables called index_stats, which, sadly, is overlaid after each command.
To get
the full picture, we must devise a table structure that will collect data from
both sources. Here is a method that will do the job:
-
Create a
temporary table to hold data from dba_indexes and index_stats
-
Verify
quality of dbms_stats analysis
-
Populate
temporary table from dba_indexes
-
Validate
indexes and send output into temp table
IMPORTANT: Collecting
the index_stats information is very time consuming and expensive and will
introduce serious locking issues on production databases. It is strongly
recommended that you perform these checks during scheduled downtime, or on a
representative test database.
10g note: Tested against Oracle10g
10.2.0.1.0 on Windows XP SP2, and found
IOT_REDUNDANT_PKEY_ELIM VARCHAR2(3)
DROPPED
VARCHAR2(3)
NUM_KEYS
NUMBER
Need to be defined in the table index_details, and this crashes the subsequent
table population and procedure.
Let?s
start by creating a table to hold our index data. I call this table
index_details:
drop table index_details;
Create table index_details
(
-- ********* The following is from dba_indexes ******************
OWNER_NAME VARCHAR2(30),
INDEX_NAME VARCHAR2(30),
INDEX_TYPE VARCHAR2(27),
TABLE_OWNER VARCHAR2(30),
TABLE_NAME VARCHAR2(30),
TABLE_TYPE VARCHAR2(11),
UNIQUENESS VARCHAR2(9),
COMPRESSION VARCHAR2(8),
PREFIX_LENGTH NUMBER,
TABLESPACE_NAME VARCHAR2(30),
INI_TRANS NUMBER,
MAX_TRANS NUMBER,
INITIAL_EXTENT NUMBER,
NEXT_EXTENT NUMBER,
MIN_EXTENTS NUMBER,
MAX_EXTENTS NUMBER,
PCT_INCREASE NUMBER,
PCT_THRESHOLD NUMBER,
INCLUDE_COLUMN NUMBER,
FREELISTS NUMBER,
FREELIST_GROUPS NUMBER,
PCT_FREE NUMBER,
LOGGING VARCHAR2(3),
BLEVEL NUMBER,
LEAF_BLOCKS NUMBER,
DISTINCT_KEYS NUMBER,
AVG_LEAF_BLOCKS_PER_KEY NUMBER,
AVG_DATA_BLOCKS_PER_KEY NUMBER,
CLUSTERING_FACTOR NUMBER,
STATUS VARCHAR2(8),
NUM_ROWS NUMBER,
SAMPLE_SIZE NUMBER,
LAST_ANALYZED DATE,
DEGREE VARCHAR2(40),
INSTANCES VARCHAR2(40),
PARTITIONED VARCHAR2(3),
TEMPORARY VARCHAR2(1),
GENERATED VARCHAR2(1),
SECONDARY VARCHAR2(1),
BUFFER_POOL VARCHAR2(7),
USER_STATS VARCHAR2(3),
DURATION VARCHAR2(15),
PCT_DIRECT_ACCESS NUMBER,
ITYP_OWNER VARCHAR2(30),
ITYP_NAME VARCHAR2(30),
PARAMETERS VARCHAR2(1000),
GLOBAL_STATS VARCHAR2(3),
DOMIDX_STATUS VARCHAR2(12),
DOMIDX_OPSTATUS VARCHAR2(6),
FUNCIDX_STATUS VARCHAR2(8),
JOIN_INDEX VARCHAR2(3),
-- ********* The following is from index_stats ******************
HEIGHT NUMBER,
BLOCKS NUMBER,
NAMEx VARCHAR2(30),
PARTITION_NAME VARCHAR2(30),
LF_ROWS NUMBER,
LF_BLKS NUMBER,
LF_ROWS_LEN NUMBER,
LF_BLK_LEN NUMBER,
BR_ROWS NUMBER,
BR_BLKS NUMBER,
BR_ROWS_LEN NUMBER,
BR_BLK_LEN NUMBER,
DEL_LF_ROWS NUMBER,
DEL_LF_ROWS_LEN NUMBER,
DISTINCT_KEYSx NUMBER,
MOST_REPEATED_KEY NUMBER,
BTREE_SPACE NUMBER,
USED_SPACE NUMBER,
PCT_USED NUMBER,
ROWS_PER_KEY NUMBER,
BLKS_GETS_PER_ACCESS NUMBER,
PRE_ROWS NUMBER,
PRE_ROWS_LEN NUMBER,
OPT_CMPR_COUNT NUMBER,
OPT_CMPR_PCTSAVE NUMBER
)
tablespace tools
storage (initial 5k next 5k maxextents unlimited);
(Note: the index_stats table has a column named PCT_USED even though Oracle
indexes do not allow changes to this value.)
Now that
we have a table that will hold all of the index details, the next step is to
populate the table with data from freshly-analyzed indexes. Remember, you
should always run dbms_stats to get current index statistics. Here is
the script.
insert into index_details
(
OWNER_NAME,
INDEX_NAME,
INDEX_TYPE,
TABLE_OWNER,
TABLE_NAME,
TABLE_TYPE,
UNIQUENESS,
COMPRESSION,
PREFIX_LENGTH,
TABLESPACE_NAME,
INI_TRANS,
MAX_TRANS,
INITIAL_EXTENT,
NEXT_EXTENT,
MIN_EXTENTS,
MAX_EXTENTS,
PCT_INCREASE,
PCT_THRESHOLD,
INCLUDE_COLUMN,
FREELISTS,
FREELIST_GROUPS,
PCT_FREE,
LOGGING,
BLEVEL,
LEAF_BLOCKS,
DISTINCT_KEYS,
AVG_LEAF_BLOCKS_PER_KEY,
AVG_DATA_BLOCKS_PER_KEY,
CLUSTERING_FACTOR,
STATUS,
NUM_ROWS,
SAMPLE_SIZE,
LAST_ANALYZED,
DEGREE,
INSTANCES,
PARTITIONED,
TEMPORARY,
GENERATED,
SECONDARY,
BUFFER_POOL,
USER_STATS,
DURATION,
PCT_DIRECT_ACCESS,
ITYP_OWNER,
ITYP_NAME,
PARAMETERS,
GLOBAL_STATS,
DOMIDX_STATUS,
DOMIDX_OPSTATUS,
FUNCIDX_STATUS,
JOIN_INDEX
)
select * from dba_indexes
where owner not like 'SYS%'
;
Now that
we have gathered the index details from dba_indexes, we must loop through
iterations of the analyze index xxx validate structure command to populate our
table with other statistics. Here is the script that I use to get all index
details.
/* INDEX.STATS contains 1 row from last execution */
/* of ANALYZE INDEX ... VALIDATE STRUCTURE */
/* We need to loop through validates for each */
/* index and populate the table. */
DECLARE
v_dynam varchar2(100);
cursor idx_cursor is
select owner_name, index_name from index_details;
BEGIN
for c_row in idx_cursor loop
v_dynam := 'analyze index '||c_row.owner_name||'.'||c_row.index_name||
' validate structure';
execute immediate v_dynam;
update index_details set
(HEIGHT, BLOCKS, NAMEx, PARTITION_NAME, LF_ROWS, LF_BLKS,
LF_ROWS_LEN, LF_BLK_LEN, BR_ROWS, BR_BLKS, BR_ROWS_LEN,
BR_BLK_LEN, DEL_LF_ROWS, DEL_LF_ROWS_LEN, DISTINCT_KEYSx,
MOST_REPEATED_KEY, BTREE_SPACE, USED_SPACE, PCT_USED,
ROWS_PER_KEY, BLKS_GETS_PER_ACCESS, PRE_ROWS, PRE_ROWS_LEN,
OPT_CMPR_COUNT, OPT_CMPR_PCTSAVE)
= (select * from index_stats)
where index_details.owner_name = c_row.owner_name
and index_details.index_name = c_row.index_name;
if mod(idx_cursor%rowcount,50)=0 then
commit;
end if;
end loop;
commit;
END;
/
update
index_details a
set
num_keys =
(select
count(*)
from
dba_ind_columns b
where
a.owner_name = b.table_owner
and
a.index_name = b.index_name
)
;
After
running the script from listing 3, we should now have complete index details for
any index that we desire. However with 70 different metrics for each index, it
can be quite confusing about which columns are the most important. To make
queries easy, I create a view that only displays the columns that I find the
most interesting. Here is my view.
drop view indx_stats;
Create view idx_stats
as
select
OWNER_NAME ,
INDEX_NAME ,
INDEX_TYPE ,
UNIQUENESS ,
PREFIX_LENGTH ,
BLEVEL ,
LEAF_BLOCKS ,
DISTINCT_KEYS ,
AVG_LEAF_BLOCKS_PER_KEY ,
AVG_DATA_BLOCKS_PER_KEY ,
CLUSTERING_FACTOR ,
NUM_ROWS ,
PCT_DIRECT_ACCESS ,
HEIGHT ,
BLOCKS ,
NAMEx ,
PARTITION_NAME ,
LF_ROWS ,
LF_BLKS ,
LF_ROWS_LEN ,
LF_BLK_LEN ,
BR_ROWS ,
BR_BLKS ,
BR_ROWS_LEN ,
BR_BLK_LEN ,
DEL_LF_ROWS ,
DEL_LF_ROWS_LEN ,
DISTINCT_KEYSx ,
MOST_REPEATED_KEY ,
BTREE_SPACE ,
USED_SPACE ,
PCT_USED ,
ROWS_PER_KEY ,
BLKS_GETS_PER_ACCESS ,
PRE_ROWS ,
PRE_ROWS_LEN ,
num_keys,
sum_key_len
from
Index_details;
While
most of these column descriptions are self-evident, there are some that are
especially important:
-
CLUSTERING_FACTOR: This is one of the most important index statistics because it indicates how
well sequenced the index columns are to the table rows. If
clustering_factor is low (about the same as the number of
dba_segments.blocks in the table segment) then the index key is in the
same order as the table rows and index range scans will be very efficient, with
minimal disk I/O. As clustering_factor increases (up to
dba_tables.num_rows), the index key is increasingly out of sequence with
the table rows. Oracle?s cost-based SQL optimizer relies heavily upon
clustering_factor to decide whether to use the index to access the
table.
-
HEIGHT
- As an
index accepts new rows, the index blocks split. Once the index nodes have
split to a predetermined maximum level the index will: spawn? into a new
level.
-
BLOCKS: This is the
number of blocks consumed by the index. This is dependent on the
db_block_size. In Oracle9i and beyond, many DBAs create b-tree indexes in
very large blocksizes (db_32k_cache_size) because the index will spawn less.
Robin Schumacher has noted in his book
Oracle Performance Troubleshooting notes: As
you can see, the amount of logical reads has been reduced in half simply by
using the new 16K tablespace and accompanying 16K data cache. Clearly, the
benefits of properly using the new data caches and multi-block tablespace
feature of Oracle9i and above are worth your investigation and trials in your
own database.?
-
PCT_USED: This
metric is very misleading because it looks identical to the dba_tables pct_used column, but has a different meaning. Normally, the
pct_used
threshold is the freelist unlink threshold, while in index_stats
pct_used is the percentage of space allocated in the b-tree that is being
used.
Is there a criterion
for index rebuilding?
If we
believe the anecdotal reports that index rebuilding improved end-user reported
performance, how can we analyze this data and see what the criteria (if any)
might be for an index rebuild?
For example, here are the criteria used by
a fellow Oracle DBA who swears that rebuilding indexes with these criteria has a
positive effect on his system performance:
-- ***
Only consider when space used is more than 1 block ***
btree_space > 8192
and
-- *** The number of index levels is > 3 ***
(height > 3
-- *** The % being used is < 75%
***
or pct_used < 75
-- *** Deleted > 20% of total
***
or (del_lf_rows/(decode(lf_rows,0,1,lf_rows)) *100) > 20)
;
In
reality I suspect that the rules are far more complicated than this simple
formula. To see the commonality between indexes of similar nature you can use
the data from your new index_details table to write summary queries
(Listing 5). Here we see the average number of index blocks, leaf rows and leaf
blocks for indexes of different heights.
This
gives us a high-level idea of Oracle threshold for spawning an index onto new
levels. We can take this same approach and attempt to answer the following
questions:
1 - At what point does an index spawn to another level
(height)? It should be a function of blocksize, key length and the number of
keys.
2 - The number of deleted leaf nodes may not be enough to
trigger an index rebuild. This is because if clustering_factor is low (dba_indexes.clustering_factor
~= dba_segments.blocks), then the rows are added in order, and the index
is likely to reuse the deleted leaf nodes. On the other hand, if
clustering_factor is high (dba_indexes.clustering_factor ~=
dba_tables.num_rows), and the majority of queries use the index with
fast-full scans or index range scans, then a rebuild of the underlying table (to
resequence the
rows) may be beneficial.
To illustrate, assume I have an index on the last_name column of a
1,000,000 row table and the clustering_factor is close to the number of
blocks, indicating that the rows are in the same sequence as the index.
In this case, a bulk delete of all people whose
last_name begins with the letter: K? would leave a dense cluster of deleted
leaf nodes on adjacent data blocks within the index tablespace. This large
section of space is more likely to be reused than many tiny chunks.
We can
also use the data from our detail table to compute our own metrics. In the
example query below, we create a meta-rule for indexes:
-
Dense
Full Block Space
- This is the index key space (number of table rows * index key length) as a
function of the blocksize and free index space.
-
Percent
of Free Blocks -
This is the estimated number of free blocks within the index.
Using
these metrics, we can analyze the system and produce some very interesting
reports of index internals:
col c1 heading 'Average|Height' format 99
col c2 heading 'Average|Blocks' format 999,999
col c3 heading 'Average|Leaf|Rows' format 9,999,999,999
col c4 heading 'Average|Leaf Row|Length' format 999,999,999
col c5 heading 'Average|Leaf Blocks' format 9,999,999
col c6 heading 'Average|Leaf Block|Length' format 9,999,999
select
height c1,
avg(blocks) c2,
avg(lf_rows) c3,
avg(lf_rows_len) c4,
avg(lf_blks) c5,
avg(lf_blk_len) c6
from
index_details
group by
height
;
Average Average Average
Average Average Leaf Leaf Row Average Leaf Block
Height Blocks Rows Length Leaf Blocks Length
------- -------- -------------- ------------ ----------- ----------
1 236 12 234 1 7,996
2 317 33,804 691,504 106 7,915
3 8,207 1,706,685 41,498,749 7,901 7,583
4 114,613 12,506,040 538,468,239 113,628 7,988
As we
see, we can compute and spin this data in an almost infinite variety of ways.
Reader Comments on index rebuilding:
It has been my experience that the percentage of deletes
required to affect performance actually goes down as the table gets larger,
perhaps because the I/O effect is magnified with more data.
At my previous job, our observation was that on 20 million
row tables and upward as little as 5% deletes, regardless of other factors,
would cause sufficient performance degradation to justify an index rebuild.
Admittedly this was a site with fairly tight budget constraints, so we couldn't
afford absolute, top of the line hardware. We also didn't have the luxury of
making sure every tablespace was ideally placed for performance, but we did a
pretty good job with what we had. I actually wrote a script that would
calculate the % deletes and generate the index rebuild command.
Also, there is the rebuild online option for indices, which does work but it
will cause noticeable performance degradation if you try and do it during busy
times. I believe it was available in 8i, but it would generate ora-600 errors
when used on busy tables in 8i.
- O racle ACE
See my related notes on index rebuilding:
Reader Feedback:
10g usage note:
Tested against Oracle10g 10.2.0.1.0 on
Windows XP SP2, and found
IOT_REDUNDANT_PKEY_ELIM VARCHAR2(3)
DROPPED VARCHAR2(3)
NUM_KEYS NUMBER
not defined in the table index_details, and this crashes the subsequent table
population and procedure.
 |
If you like Oracle tuning, see the book "Oracle
Tuning: The Definitive Reference", with 950 pages of tuning tips and
scripts.
You can buy it direct from the publisher for 30%-off and get
instant access to the code depot of Oracle tuning scripts. |
|

|
|


