|
 |
|
Oracle Real Application Clusters and Data Warehouse Applications
Don Burleson
(Last Updated 5 September 2005)
|
Oracle has marketed the Real Application Clusters
(RAC) option as appropriate for all types of applications, but there
is some debate about whether RAC server blades are better than the
same amount of computing resources in a single server for Oracle data warehouses.
Oracle RAC
is used primarily for continuous availability of mission-critical
systems (i.e. banking applications) and for transparent scalability
of massive online transactions systems (i.e. Amazon). However, it
is may not always the best architecture for data warehouse that require
large materialized view rollups because they
often require large, cohesive RAM regions (large data sorts) and
tightly-coupled CPU's (fast parallel query).
This
Oracle whitepaper claims that special tricks to address
above-the-line SGA RAM in a 32-bit Linux environment, and correctly
notes that parallelized full-tables scans use PGA RAM:
Memory for hash joins and sort
operations is allocated out of the PGA (Program Global Area),
not the SGA. PGA memory is not bound by the 1.7GB SGA. A 4 CPU
system running a degree of parallelism of 8 uses typically less
than 3.2GB of PGA.
But the question remain whether the RAC
interconnect will be slower than a monolithic server for large-scale
parallel queries with large RAM demands, the type of queries that
are common for aggregation, rollups and materialized view
refreshing.
Some experts say that Oracle RAC is not the best solution to data
warehouse applications because they require large banks of CPU's to
perform parallel table-scan operations. Mike Ault, noted Oracle
data warehouse consultant notes "I have never heard of any shop
using RAC for a data warehouse, and I could imaging large parallel
operations clobbering the interconnect as to make RAC somewhat
sub-optimal for data warehouse processing". Ault says
that the Oracle
Server Tuning manual makes this very clear (emphasis added):
Parallel query can
dramatically improve performance for data-intensive data warehousing
operations. It helps systems scale in performance when adding
hardware resources.
The greatest
performance benefits are on symmetric multiprocessing (SMP),
clustered, or massively parallel systems where query processing can
be effectively spread out among many CPUs on a single system.
In the Oracle manual "Parallelism
and Partitioning in Data Warehouses" see see the caution that
Oracle parallel query requires SMP or MPP servers, not the 2-way or
4-way CPU's used in RAC databases:
Parallel execution benefits systems that have
all of the following
characteristics:
- Symmetric
multi-processors (SMP), clusters, or
massively parallel systems
- Sufficient
I/O
bandwidth
- Underutilized or
intermittently used CPUs (for example, systems
where CPU usage is typically less than 30%)
- Sufficient memory to support
additional memory-intensive processes such as
sorts, hashing, and I/O buffers
If your system lacks any of these
characteristics, parallel execution might not
significantly improve performance.
To see the relationship between the number of
CPU's and the degree of parallelism,
click here. Let's take a close look at the problems of
parallel query on RAC databases and see why large monolithic server
are a more optimal choice. This article offers advice on the basics of
configuration for Oracle data warehouses, and this tip emphasizes the
importance of using
multiple block sizes for all VLDB Oracle warehouse systems.
The problem of parallel query on RAC
Oracle data warehouse applications require
high-parallelism to ensure fast reads of multi-gigabyte tables using
Oracle parallel query (OPQ). In Oracle 10g, automatic parallelism
can be enabled and the degree of parallelism is controlled
internally by interrogating the number of CPU's on the server (the
cpu_count parameter) and setting the automatic degree of parallelism
based on the CPU count.

At the risk of re-stating the obvious, research
and the Oracle documentation discuss the problems with query
parallelism when the CPU's are distributed across many servers.
For a complete discussion of the types of
Oracle parallel query,
click here. According to the research "Modelling
Parallel Oracle for Performance Prediction" (Distributed and
Parallel Databases, 13, 251–269, 2003), the inter-node parallelism
is more complex that in-the-box Oracle parallel query:
The flow of a
query through the PQO starts with the user process issuing a query
or transaction. The dedicated server process parses and executes it.
It assigns work to a number of query servers depending upon the
degree of parallelism.
The query servers
split the workload and return the result data back to the dedicated
server process. The dedicated server assembles the data and returns
the results to the user process.
The Oracle manual
Database Data Warehousing Guide for Oracle 10g also explains the
performance issue of having distributed CPUs for parallel
operations:
Each server in the
producer execution process set has a connection to each server in
the consumer set. This means that the number of virtual connections
between parallel execution servers increases as the square of the
DOP.
Each communication
channel has at least one, and sometimes up to four memory buffers.
Multiple memory buffers facilitate asynchronous communication among
the parallel execution servers.
A single-instance
environment uses at most three buffers for each communication
channel. An Oracle Real Application Clusters environment uses at
most four buffers for each channel.
However, the problem of parallel query on Real
Application Clusters is just the tip of the iceberg. We also
encounter massive performance issues when attempting to sort a
result set from a RAC-based parallel query.
The problem of sorting parallel results
We have a huge overhead in sorting the result
set because the RAC nodes must transfer the data back to the
parallel query coordinator, which will reassemble the data, perform
a sort if required, and return the results back to the end user.
While this operation is transparent within a single server, in a RAC
environment, billions of bytes of table data must be passed to the
coordinator, often with disastrous performance. This diagram from
the
Oracle 10g Data Warehouse manual illustrates the process:
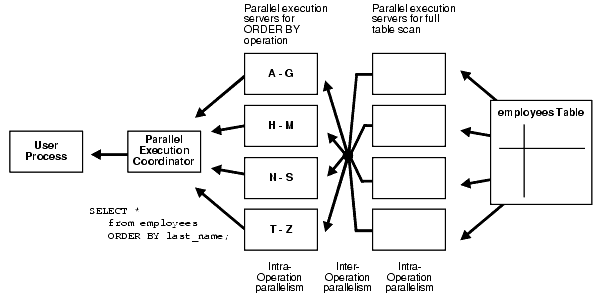
In a RAC cluster (where each node has only two
or four processors), Oracle parallel query cannot perform as-fast as
a single monolithic server. For example, a 8-node RAC configuration
with 2 processors each (16 CPUs) will be far slower for large-table
scans than a single server with 16 processors. However,
research by Richmond Shee
suggests that intelligent setting of sort_area_size
pga_aggregate_target) may allow one-pass sorts to happen nearly as
fast as optimal (in-RAM). sorts.
Even more important, it has been suggested that
using high-speed
RAM-SAM
(solid-state disk) for the
RAC TEMP tablespace might alleviate this sorting issue on RAC
systems.
One hallmark of data warehouse applications is
the requirement to perform large-table scans quickly, especially
during the critical ETL (Extract, transformation, and Load)
processing and during online analytical processing, where Oracle
must scan large volumes of data very quickly. On RAC systems with
small numbers of processors on each node, there parameters are set
based upon the cpu_count of each node.
- fast_start_parallel_rollback
- parallel_max_servers
- log_buffer
- db_block_lru_latches
Conversely, the same number of processors would
result in different settings for these parameters, often resulting
in faster performance.
Parallel Query and the Data Warehouse
The "degree" of parallelism for Oracle parallel
query is dependent upon the number of processors and the disk
configuration, but the advent of the SAME (Stripe And Mirror
Everywhere) has made the number of CPU's the primary consideration
in large-table scan performance, as noted in the book "Oracle9i RAC":
Huge amounts of
data require large numbers of disk drives, large amounts of memory,
and a significant number of CPUs if answers are to be obtained in a
timely manner.
Oracle achieves high-speed table scans in a
"divide and conquer" approach by dividing the table into equal
pieces and dedicates a separate CPU process to handle each table
section. When all processors reside within the same server,
large-table scans
For example, the speed of large-table
full-table scans is far slower on RAC systems with small numbers of
processors on each node. The inter-node parallel query on a RAC
cluster system has far higher overhead because the parallel query
coordinator must communicate with the slave processes over the
network and because the table results will have to be transferred
across the "cache fusion" bus.
Not for Everyone?
Some hardware vendors may claim
that RAC is appropriate for every types of application.
DM Review magazine noted several issues with Oracle RAC and
suggests that the primary motive for using RAC should be to achieve
continuous availability and transparent failover:
As the overall leader in the unsegmented
data warehousing market, the game is Oracle's to win or lose.
Oracle has strength, but potential vulnerabilities include:
The paradox of high availability. In its earlier incarnation,
Oracle's RAC showed what might be described as the paradox of
high availability (HA). The more moving parts that are added to
maintain system availability, the greater the likelihood that,
in the worst case, one of them will fail, resulting in the very
scenario against which the HA was supposed to be the antidote.
In
sum, Oracle Real Application Clusters is a wonderful tool for
mission-critical databases that must have continuous availability
and for
scalability of super-large OLTP systems, but the jury is still out
about whether server blades with Oracle RAC is an optimal
choice for data warehouse applications that require high-speed table
scan performance.
A Benchmark Plan
A definitive answer to this monolithic vs. RAC
question requires a benchmark test to examine optimal parallelism in a
solid-state RAC environment vs. monolithic servers. This test
could be done on a two-node RAC
cluster with two hyper-threaded 64-bit CPU's on each node.
The benchmark test should be a TPC-H (lots of large-table full-table
scans) with inter-node parallelism (2 CPU's on the same node),
intra-node parallelism (2 CPU's, one on each node), and full
parallelism (all CPU's on all two nodes). The full parallelism test
would capture elapsed time the TPC-H run with both nodes, with
intra-node parallel query.
|
