 |
|
Oracle Data Warehousing Tips
Oracle Tips by Burleson Consulting
May 2005
|
Burleson Consulting is the
USA's leading provider of expert Oracle data warehousing consulting
and support.
|
We
have Oracle certified data warehouse experts to ensure that your
data warehouse project is successful.
Just
e-mail:
 for
details on our Oracle data warehousing support services. for
details on our Oracle data warehousing support services. |
 |
Oracle
Data Warehousing Tips
by Donald K.
Burleson
The intent of this article is to show the main tools
and techniques used by the Oracle data warehouse administrator for time-series
warehouse tuning.
As corporate
data warehouse systems grow from small-scale applications into
industry-wide systems, the IT manager must be in a posture to grow
without service interruption. Oracle fills this niche with
their database that allows infinite scalability, but the IT manager
must also choose server hardware that allows seamless growth.
What
Does a Data Warehouse Need?
Since the
earliest days of Decision Support Systems (DSS) of the 1960s, database
professionals have recognized that internal processing for data
warehouse applications is very different from Online Transaction
Processing Systems (OLTP).
Data warehouse
applications tend to be very I/O intensive, as the database reads
trillions of bytes of information. Data warehouse systems require
specialized servers that can support the typical processing that we
see in data warehouses. Most data warehouses are bi-modal and have a
batch windows (usually in the evenings) when new data is loaded,
indexed, and summarized. The server must have on-demand CPU and RAM
resources, and the database management system must be able to
dynamically reconfigure its resources to accommodate these shifts in
processing.
Back in the
1970s, Moore's law was developed; it stated that processor costs are
always falling while speed continues to improve. However, Moore's law
does not apply to RAM.
While RAM costs
continue to fall ever year, the speed of RAM access is constrained by
silicon technology and has not improved in the past three decades
(refer to Figure 1).

Figure 1: Speed improvements of CPU vs. RAM.
Because RAM
speed has not improved as CPU speed has improved, RAM must be
localized near the CPUs to keep them running at full capacity, and
this is a central feature of many of the new Intel-based servers.
Non-Uniform Memory Access (NUMA) has been available for years in
high-end UNIX servers running SMP (symmetric multi-processor)
configurations.
To process large
volumes of data quickly, the server must be able to support parallel,
large-table-full-table scans for data warehouse aggregation. One of
the most significant improvements in multi-CPU servers is their
ability to utilize Oracle parallel features for table summarization,
aggregation, DBA maintenance (table reorganization), and parallel data
manipulation.
For example,
this divide-and-conquer approach makes large-table-full-table scans
run seven times faster on an eight-CPU server and 15 times faster on a
16-way SMP server (refer to Figure 2).

Figure 2: Data Warehouse large-table-full-table scans
can be parallelized for
super-fast response.
Historically,
data warehouse applications have been constrained by I/O, but all of
this is changing with the introduction of specialized data warehouse
techniques, all with the goal of keeping the server CPUs running at
full capacity.
Now, while the
automated features of Oracle AMM, ASM, and automatic query re-write
simplify the role of the Oracle DBA, savvy Oracle
DBAs leverage other advanced Oracle features to get
super-fast data warehouse performance:
-
Materialized
Views
— The Oracles materialized views (MV) feature uses Oracle
replication to allow you to pre-summarize and pre-join tables. Best
of all, Oracle MVs are integrated with the Oracle query
re-write facility, so that any queries that might benefit from the
pre-summarization will be automatically rewritten to reference the
aggregate view, thereby avoiding a very expensive (and unnecessary)
large-table-full-table scan. The Oracle dbms_advisor
utility will automatically detect and recommend MV definitions, then
create a materialized view to reduce disk I/O.
-
Automated
Workload Repository
— The AWR is a critical component for data warehouse predictive
tools such as the
dbms_advisor
package. AWR allows you to run time-series reports of SQL access
paths and intelligently create the most efficient materialized views
for your warehouse. The AWR provides a time-series component of
warehouse tuning that is critical for the identification of
materialized views and holistic warehouse tuning. The most important
data warehouse tracking with AWR includes tracking
large-table-full-table scans, hash joins (which might be replaced
with STAR joins), and tracking RAM usage within the
pga_aggregate_target
region.
-
Multiple
Blocksizes
— All data warehouse indexes that are accessed via range scans and
Oracle objects that must be accessed via full-table, or full-index,
scans should be in a 32k blocksize.
-
STAR query
optimization
— The Oracle STAR query features make it easy to make
complex DSS queries run at super-fast speeds.
-
Multi-level
partitioning of tables and indexes
— Oracle now has multi-level intelligent partitioning methods that
allow Oracle to store data in a precise scheme. By controlling where
data is stored on disk, Oracle SQL can
reduce the disk I/O required to service any query.
-
Asynchronous
Change Data Capture
— Change data capture allows incremental extraction, so only changed
data to be extracted easily. For example, if a data warehouse
extracts data from an operational system on a weekly basis, then the
data warehouse requires only the data that has changed since the
last extraction (that is, the data that has been modified in the
past seven days).
-
Oracle Streams
— Streams-based feed mechanisms can capture the necessary data
changes from the operational database and send it to the destination
data warehouse. The use of redo information by the streams capture
process avoids unnecessary overhead on the production database.
-
Read-only
Tablespaces
— Documents from
Oracle Magazine and Oracle Press suggest that using tablespace partitions and marking
the older tablespaces as read-only can improve performance up to 10%.
However, not everyone agrees.
For more details, read Robert
Freeman's excellent discussion of
read-only
tablespace performance.
-
Automatic Storage
Management (ASM)
— The revolutionary new method for managing the disk I/O subsystem
removes the tedious and time-consuming chore of I/O load balancing
and disk management. With Oracle ASM, all disks can be
logically clustered together into disk groups, and data files can be
spread across all devices using the Oracle SAME (stripe
And Mirror Everywhere) standard. By making the disk back-end a JBOD
(Just a Bunch Of Disks), Oracle manages this critical
aspect of the data warehouse.
-
Advanced Data
Buffer Management
— Using Oracle's multiple block sizes and KEEP pool, you
can preassign warehouse objects to separate data buffers and ensure
that your working set of frequently-referenced data is always
cached. Small, frequently-referenced dimension tables should be
cached using the Oracle KEEP pool. Oracle also
offers Automatic Memory Management (AMM). With this feature,
Oracle will automatically re-assign RAM frames between the
db_cache_size and the pga_aggregate_target
region to maximize throughput of your data warehouse.
All of these
techniques have helped to remove I/O bottlenecks and to make data
warehouse applications more CPU intensive. There are many server
resources that are required for all large data warehouse applications.
These features include:
-
Large RAM Regions
— All 64-bit servers have a larger word size (two to the 64th power)
that allows for up to 18 billion GB (that's 18 exabytes). This
allows for huge scalability as the processing demand grows and
allows the database to have many gigabytes of data buffer storage.
-
Fast CPU
— Intel's 64-bit Itanium 2 architecture is far faster than the older
32-bit chipsets. The advanced features built into the Itanium 2
chipset allow much more real work to be done for each processor
cycle. When combined with the Oracle NUMA RAM,
computationally-intensive DSS queries run at lightening speeds.
-
High parallelism
— Each processing node has four Itanium 2 CPUs interconnected to
local memory modules and an inter-node crossbar interconnect
controller via a high-speed bus. Up to four of these processing
nodes can be interconnected, creating a highly scalable SMP system.
This design allows large-scale parallel processing for Oracle
full-table scans — the scattered reads that are the hallmark of
Oracle warehouse systems. For example, the new 64-bit servers
support up to 64 processors, allowing for large parallel benefits.
-
High Performance
I/O architecture — The I/O subsystem also influences scalability and performance.
Enterprise systems must provide the channel capacity required to
support large databases and networks. The Itanium 2 system
architecture can support up to 64 peripheral component interconnect
(PCI or PCI-X) 64-bit channels operating at speeds from 33 MHz to
100 MHz.
The advent of large
RAM regions is also beneficial for the data warehouse. In most data
warehouses, a giant, central "fact" table exists, surrounded by
smaller dimension tables (refer to Figure 3).
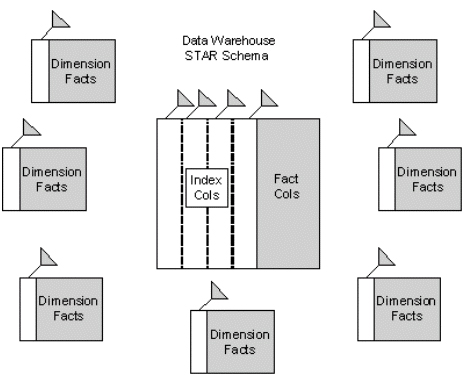
Figure 3: A typical data warehouse schema.
In a typical
STAR schema, the super-large full-table scans can never be cached, but
it is important to be able to control the caching of the dimension
tables and indexes. When using a 64-bit server with fast RAM access,
the Oracle KEEP pool and multiple buffer caches can be configured to
guarantee that the smaller, frequently-referenced objects always
remain in the data buffers, thereby shifting the database bottleneck
away from I/O. Once we shift the bottleneck from I/O to CPU, we are in
a position to scale performance by adding additional processors.
Why
Oracle for the Data Warehouse?
The large data
buffer caches in most OLTP Oracle systems make them CPU-bound, but
Oracle data warehouses are another story. With terabytes of
information to aggregate and summarize, most Oracle data warehouses
are I/O-bound, and you must choose a server that optimizes disk I/O
throughput.
Oracle has
always made very large database (VLDB) technology a priority as
evidenced by their introduction of partitioned structures, advanced
bitmap indexing, and materialized views. Oracle now provides
some features that are ideal for the data warehouse application.
You can easily
see when an Oracle warehouse is disk I/O bound. In the following AWR
report (STATSPACK report for Oracle9i and earlier), you can see a
typical data warehouse system that is clearly constrained by disk I/O,
resulting from the high percentage of full-table and full-index scans.

A STATSPACK (AWR) Top 5 Timed Event Report for an I/O-bound
Server
Here you can see
that scattered reads (full-table scans) constitute the majority of the
total database time. This is very typical of a data warehouse that
performs aggregations via SQL and it is also common during the
"refresh" period for Oracle materialized views. The problem is the I/O
bottleneck that is introduced during these periods.
Because the
typical data warehouse is so data intensive, there is always a problem
fully utilizing the CPU power. UNISYS has addressed this issue by
leveraging NUMA, whereby Windows and Oracle are
automatically configured to exploit NUMA to keep the CPUs busy.
(Remember, the data buffer hit ratio is not relevant for data
warehouses or for systems that commonly perform full-table scans or
those that use
all_rows SQL
optimization.)
While a 30 GB
db_cache_size
might be appropriate for an OLTP shop or a shop that uses a large
working set, a super-large SGA does not benefit data warehouses and
decision support systems in which most data access is performed by a
parallelized full-table scan. When Oracle performs a parallel
full-table scan, the database blocks are read directly into the
program global area (PGA), bypassing the data buffer RAM (refer to
Figure 4).

Figure 4: Parallel Full Scans Bypass SGA data buffers.
As we see in the
figure above, having a large
db_cache_size
does not benefit parallel large-table-full-table scans, as this
requires memory in the
pga_aggregate_target
region instead. With Oracle, you can use the multiple data
buffer features to segregate and cache your dimension tables and
indexes, all while providing sufficient RAM for the full scans. When
your processing mode changes (evening ETL and rollups), Oracle
AMM will automatically detect the change in data access and
re-allocate the RAM regions to accommodate the current processing.
All 64-bit
servers have a larger word size (two to the 64th power) that allows
for up to 18 billion GB of addressable RAM. Hence, you may be tempted
to create a super-large RAM data buffer. Data warehouse systems tend
to bypass the data buffers because of parallel full-table scans, and
maximizing disk I/O throughput is the single most critical bottleneck.
Most SMP servers
have a specialized high-speed RAM called an L2 cache that is localized
near the CPUs (refer to Figure 5).

Figure 5: The Non-uniform Memory access architecture.
Best of all,
Oracle has been enhanced to recognize NUMA systems and
adjust memory and scheduling operations accordingly. NUMA technology
allows for faster communication between distributed memory in a
multi-processor server. Better than the archaic UNIX implementations
of the past decade, NUMA is fully supported by Linux and Windows
Advanced Server 2003, and Oracle can now better exploit high-end NUMA
hardware in SMP servers.
AWR and
the Data Warehouse
One important
use for the AWR tables is tracking table join methods over time and
this is especially important for ensuring that your star schema
queries are using the fastest table join method. Let's look at a query
that produces a table join exception report.
As we know, the
choice between a hash join, star transformation join, and a nested
loop join depends on several factors:
-
The relative number of rows in each table
-
The presence of indexes on the key values
-
The settings for static parameters such as index_caching
and cpu_costing
-
The current setting and available memory in
pga_aggregate_target
As we know, hash
joins do not use indexes and perform full-table scans (often using
parallel query). Hence, hash joins with parallel full-table scans tend
to drive up CPU consumption.
Also, PGA memory
consumption becomes higher when we have hash joins, but if AMM is
enabled, then that's not usually a a problem.
Let's look at a
query that produces a report alerting an Oracle DBA when a hash join
operation count exceeds some threshold:
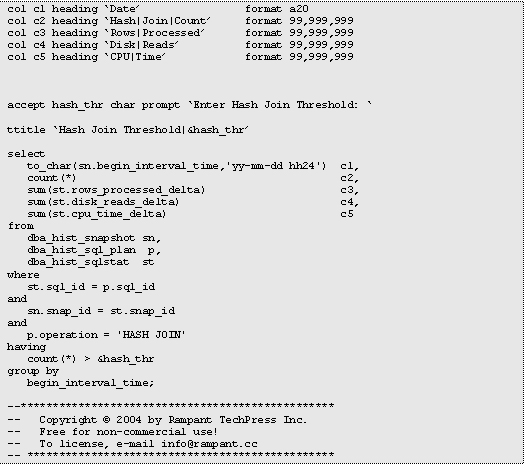
The sample
output might look like this, showing the number of hash joins during
the snapshot period along with the relative I/O and CPU associated
with the processing. Note that the values for
rows_processed
are generally higher for hash joins (which do full-table scans) as
opposed to nested-loop joins, which generally involve a very small set
of returned rows.
Hash
Join Thresholds

The previous script can be easily modified to track star
transformation joins.
Be
careful in Oracle9i
As a related
sidenote, in Oracle9i, the sorting default is that no single task may
consume more than five percent of the pga_aggregate_target
region before the sort pages-out to the TEMP tablespace for a disk
sort. For parallel sorts, the limit is 30 percent of the PGA
aggregate, regardless of the number of parallel processes.
Be aware that in
Oracle9i, when you set pga_aggregate_target,
no single hash join may consume more than five percent of the area. If
you have specialized hash joins that require more hash area.
To force hash
joins in Oracle9i, you must take two steps. It may not be enough to
increase the hash_area_size
if the CBO is stubborn, and you may need to force the hash join with a
hint.
Step 1
— Increase the hash_area_size maximum
alter session set workarea_size_policy=manual;
alter session set hash_area_size=1048576000;
Step 2
—
Add a use_hash hint to the SQL
select /*+ use_hash(a, b)*/
from . . .
Conclusion
Oracle Database
has never been better for managing very large databases. My
favorite new features are the ability to track SQL execution over time
and to employ Oracle partitioning, materialized views, and start
transformation joins for super-fast data access.
|

