|
 |
|
Inside Oracle Parallel Query
Don Burleson
May 25, 2005 |
When we talk about parallelism in
Oracle, there are several types of parallel query to consider:
-
Single-instance parallel query - This is
when a single instance fires-off multiple processes to read
sections of a large table at the same time. A parallel query
coordinator then merges the results from each PQ factotum
process.
-
RAC inter-instance parallel query - In a
clustered environment, Oracle RAC can perform large-table
full-table scans in parallel using separate processes on each
node.
-
Distributed parallel query - In
distributed databases when a table has been partitioned into
separate instances, a parallel query can be invoked to read the
remote tables simultaneously.
This article explores the
differences between a monolithic server and a RAC clusters for
parallelizing large-table full-table scans and exposes some of the
differences between single-instance and inter-instance parallelism.
For our examples below let's
assume two architectures with equal hardware resources of 16 CPU's
and 32 gigabytes of RAM. We will be reading a sales table that
resides on 1,000,000 blocks. Each of these systems has the same
total resources, 16 processors and 32 gig of RAM:
-
Monolithic server - 16 processors, 32 gig
RAM
-
RAC servers - Four nodes, each with 4
processors and 8 gigabytes of RAM
A common requirement of Oracle
data warehouses are rollup and aggregation processes whereby
super-large tables are read, end-to-end, computing summary and
average values. Some data warehouse queries also have ORDER BY or
GROUP BY clauses, requiring Oracle to retrieve and sort a very-large
result set. In our examples, assume that we are running a rollup
query against a ten-million row table to sum all sales for one
million distinct customers. To see the relationship between
the number of CPU's and the degree of parallelism,
click here.
Let's start our discussion with a
review of Standard Oracle parallel query than then look at Oracle
parallel query for RAC. We will also examine a third type of
inter-instance parallel query, Oracle Parallel Query in a
distributed environment.
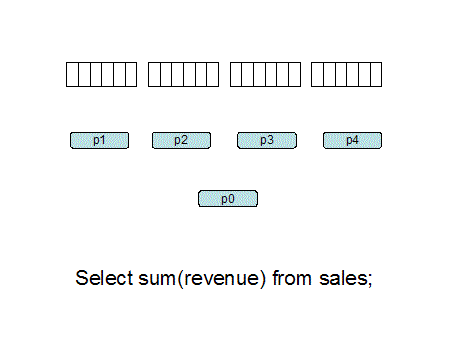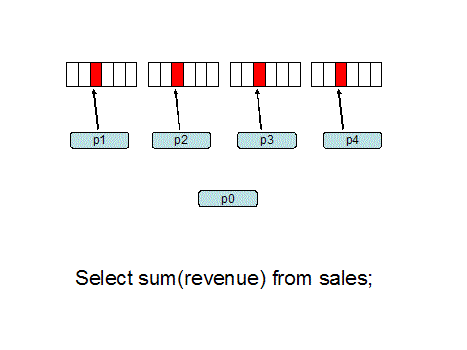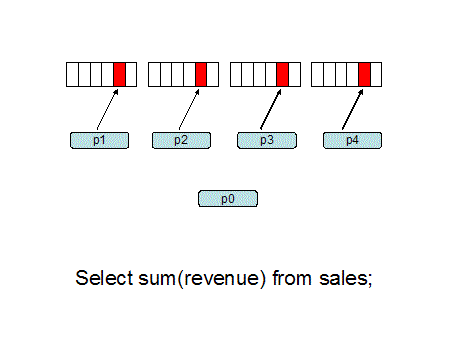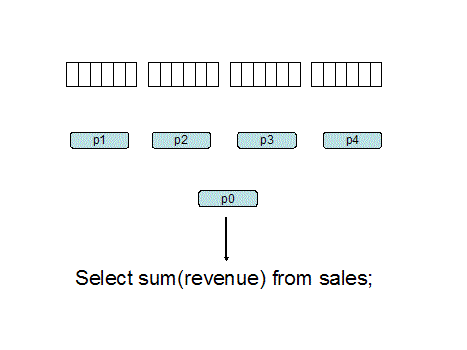
Single-instance Oracle Parallel
Query
In a single-instance environment
we are able to dedicate as many resources as we desire. In the
example below we use 15 PQ slave (factotum) processes and allocate
16 gigabytes to sort the result set in RAM:
alter session set sort_area_size = 16384000000;
SELECT /*+ FULL(sales) PARALLEL(sales, 15) */
customer_name,
sum(purchase_amount)
from
sales
group by
customer_name;
Pictorially, the parallel query
would look like this, with 16 simultaneous background processes
(e.g. P000, P001) reading the one million table blocks.

As each factotum (slave) process
ends (at almost the same time), they pass the result set to the PQ
coordinator and the sort is perform within the 16 gig RAM sorting
region.
Oracle
RAC and Inter-Instance parallelism
The foundation of Oracle Real
Application Clusters revolves around parallelism, and long-term
Oracle professionals remember that the original name for RAC was
OPS, for Oracle Parallel Server.
With RAC, it is possible for an
intra-parallel operation to utilize the processors across the nodes,
using the second argument in the Oracle PARALLEL hint. That
gives an additional degree of parallelism while executing in
parallel. For instance, a parallel query can be set up with 'Parallel Hint' to utilize
the CPUs from the many RAC instances.
Because each node requires a
parallel query coordinator, many shops use n-1 parallelism, to
reserve a CPU for the query coordinator. If we have four instances,
each with 4 CPU's, our query might use a degree of parallelism (DOP)
of 3 (n-1, to reserve a CPU for the query coordinator process).
MOSC note 280939.1 confirms that a separate parallel query
coordinator is required on each remote node:
The
slaves are controlled by the user background process (called query
coordinator QC ). In RAC environment the slaves for one query maybe
be are spawned on different Nodes. . . .
Parallel execution does not allocate slaves randomly across the
available instances, but rather will start by allocating on the
least loaded instance. The goal is to both minimize inter-node
traffic and at the same time try to minimize any imbalance of work
across the instances.
The
INSTANCE_GROUPS/PARALLEL_INSTANCE_GROUP parameter can be used to
restrict allocation of query slaves to specific instances in a
RAC configuration and over-ride the automatic allocation across
instances. This can improve the performance when there are
problem with the inter-connect.
Hence, the query might look like
this, with a DOP of three:
SELECT /*+ FULL(sales) PARALLEL(sales, 3,4) */
customer_name,
sum(purchase_amount)
from
sales;
In this example, the DOP is three
and we use all four instances. The query is executed with a total of
16 processes, 4 on each instance, and one parallel query coordinator
on each instance:

From the illustration it becomes
clear that the RAC implementation of the query might run slower than
an equivalent query on a monolithic server with the same hardware.
Note the differences between this RAC query and the vanilla Oracle
parallel query on the monolithic server:
-
One-fourth fewer processes reading the table
rows - We must reserve a process for the parallel query
coordinator on each node.
-
Overhead on the cache fusion layer - As
each node delivers the result set, the rows must be transferred
to the master node that is controlling the query.
-
Slower sorting - Because the master node
only has 8 gig of RAM, the result set is too large to sort
in-memory and a time-consuming disk sort is required.
For more on using Oracle Real Application Clusters
in a data warehouse,
click here.
Parallel Query for distributed
instances
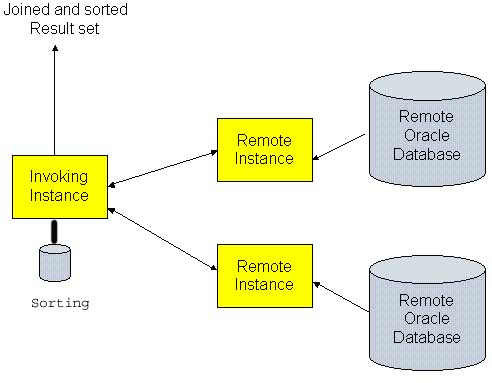
In a distributed environment,
pieces of a table may reside on many remote servers. For example,
assume that we have a distributed architecture where local customer
tables are kept on each instance. You could access all of the
remote rows in a single query, using inter-instance parallel
execution. In this example, the query is executed from the
north_carolina instance, accessing two remote instances in-parallel:
select customer_name, sum(purchase_amount)
from sales
union
select customer_name, sum(purchase_amount)
from sales@san_francisco
union
select customer_name, sum(purchase_amount)
from sales@new_york
group by
customer_name;
In this case the north_carolina
instance drives the distributed parallel query and it is the
north_carolina instance that must gather and sort the result set.
As we see, Oracle offers a wealth
of distributed parallel query options, each with its own unique
characteristics.
|


