 |
|
The latest consensus on multiple blocksizes
Oracle Database Tips by Donald BurlesonLast updated February 27, 2015
|
For those who require proof scripts, please
see how an
Oracle
tuning Guru achieves 20x performance improvement by changing blocksizes.
The Oracle? Database Administrator's Reference 10g Release 2 (10.2) for
UNIX-Based Operating Systems notes these guidelines for choosing the best
Oracle blocksizes:
Oracle recommends smaller Oracle Database block sizes (2
KB or 4 KB) for online transaction processing (OLTP) or mixed workload
environments and larger block sizes (8 KB, 16 KB, or 32 KB) for decision
support system (DSS) workload environments.
The Oracle 11.2
Database Performance Tuning Guide notes the advantages and
disadvantages of different blocksizes:
Block Size Advantages
Smaller
blocksize:
- Good for small rows with lots of random access.
-
Reduces block contention.
Larger blocksize:
- Has
lower overhead, so there is more room to store data.
- Permits reading
several rows into the buffer cache with a single I/O (depending on row size
and block size).
- Good for sequential access or very large rows (such as
LOB data).
Block Size Disadvantages
Smaller
blocksize:
- Has relatively large space overhead due to metadata
(that is, block header).
- Not recommended for large rows. There might
only be a few rows stored for each block, or worse, row chaining if a single
row does not fit into a block.
Larger blocksize:
- Wastes
space in the buffer cache, if you are doing random access to small rows and
have a large block size. For example, with an 8 KB block size and 50 byte
row size, you waste 7,950 bytes in the buffer cache when doing random
access.
- Not good for index blocks used in an OLTP environment, because
they increase block contention on the index leaf blocks.
WARNING: Using
multiple blocksizes effectively is not simple. It requires expert-level
Oracle skills and an intimate knowledge of your I/O landscape. While
deploying multiple blocksizes can greatly reduce I/O and improve response time,
it can also wreak havoc in the hands of inexperienced DBA's. Using
non-standard blocksizes is not recommended for beginners.
The use of multiple blocksizes in very large databases
(VLDB) is more than 20 years old, and corporations have been using multiple
blocksizes in the IDMS database with proven success since the 1980's.
There are well-documented reports of different response times using identical
data and workloads with multiple block sizes. This overview covers the
following topics:
For most databases, creating multiple blocksizes is not
going to make a measurable difference, and the deployment of multiple blocksizes
must be carefully evaluated on a case-by-case basis. The DBA must
carefully evaluate their database for I/O patterns and buffer efficiency to see
if multiple blocksizes are right for their unique system.
You can choose your blocksize from the DBCA screen
While it is generally accepted that multiple
blocksizes are not for every shop, they may be appropriate for large
multi-terabyte databases where the DBA wants to incur the additional
monitoring complexity to be able to control their I/O buffers at a
lower-level of granularity.
For example, insert-intensive databases will perform less
write I/O (via the DBWR process) with larger block sizes. This is because
more "logical inserts" can take place within the data buffer before the block
becomes full and requires writing it back to disk. Some shops define their
high-insert tablespaces in a larger blocksize to minimize I/O, and some use SSD
to achieve insert speeds of over 10,000 rows per second.
For a more complete discussion, see my
Oracle Multiple blocksize tips.
Our experience with different blocksizes
BC has seen dozens of cases where changing the blocksize can have a profound
impact on overall performance, both in response time and throughput performance,
and the choice of blocksize is one of the most important tuning considerations.
BC recently had a server running Oracle 9.2.0.8. Two instances on the
machine, each with the EXACT same parameters except for DB_BLOCK_SIZE, all files
located on the EXACT same mounts.
When the 16k instance runs an 850,000 row update (no where clause), it finishes
in 45 minutes. When the 4k instance runs an 850,000 row update (no where
clause), it finishes in 2.2 minutes. The change in blocksize caused the job to
run TWENTY TIMES FASTER.
A client has an update that they must run (unfortunately) which updates
~830,000 rows, setting one column equal to the other (two column table). On
their development environment this was taking roughly twenty seconds to perform.
However, on their soon-to-be production environment it was taking roughly 45
minutes.
Explain plans were checked, trace files examined, and not much popped up
except that the production machine was attempting larger I/Os during the update
and was consequently taking much longer. Comparing the initialization parameters
between production and development showed the exact same parameters, except that
the upcoming production box was using a 16k block size and development was using
a 4k block size.
The final result: When the update was run against the 16k blocksize DB, it
took 45 minutes. Against the 4k blocksize DB on the same box with the same
parameters and the same FS mounts, it took 2 minutes 20 seconds.
I even took it a step further to see if we could squeeze any more performance
out of it. Setting FILESYSTEMIO_OPTIONS=SETALL (instead of none) I was able to
get the update down to 1.5 minutes. Turning off DB_BLOCK_CHECKING (not
recommended) I was able to get it down to 10 seconds.
By going from a 16k blocksize to a 4k blocksize with all other things being
equal, we experienced roughly a twenty times improvement. We shaved off even
more time setting FILESYSTEMIO_OPTIONS = SETALL. And then we changed
DB_BLOCK_CHECKING, a parameter Oracle documentation says only adds a 1 to 10%
overhead depending on concurrency of DML, which made the update 6 times faster
alone.
The final result was a 270 times improvement over the original, changing only
the db_block_size. To be fair, I also tried setting the
FILESYSTEMIO_OPTIONS and DB_BLOCK_CHECKING the same on the 16k blocksize
instance, which resulted in the update taking 30 minutes as opposed to 45. The
results were better, but the 4k blocksize database still won by 180 times.
What's more, all queries, both large and small, performed the same or better
than in production, and a test insert of 100,000 rows went from 20 seconds on
the 16k blocksize to 3 seconds on the 4k.
While this experiment definitely shows that changing only blocksize can have
a profound effect, more thorough analysis will help get to the core of why
changing blocksizes had such a positive tuning effect.
Oracle Ace Ben Prusinski notes that batch jobs can see a 3x
performance improvement when moved to a larger blocksize:
"My experiences have been that using different block sizes can make a
difference.
For a past customer a large financial company, we improved database
performance by increasing block size from 8k blocksize to 16k blocksize.
Performance for nightly data loads went down from 22 hours to 6 hours when
we increased the database block size."
What are the benefits of using
multiple data buffers?
The nature of multiple data buffers changes between
releases. In Oracle 8i, the KEEP and RECYCLE pools were a sub-set of the
DEFAULT pool. Starting with Oracle9i, the KEEP and RECYCLE pools are allocated
in addition to the db_cache_size.
This
official benchmark by Oracle Corporation notes that different blocksizes
result in
The first round of benchmarking shows that larger block
sizes do consume more CPU, especially in metadata intensive workloads, but
overall read speeds are much better.
Operations on one million 16K files in one directory
|
Blocksize |
Create |
Read |
Delete |
|
4096 |
480s (244s sys) |
17m14s (3m11s sys) |
4m31s (2m15s sys) |
|
8192 |
459s (238s sys) |
15m20s (3m8s sys) |
4m28s (2m29s sys) |
|
16384 |
470s (240s sys) |
14m47s (3m8s sys) |
5m2s (3m9s sys) |
|
32768 |
521s (270s sys) |
14m39s (3m16s sys) |
7m7s (4m41s sys) |
|
65536 |
663s (362s sys) |
14m31s (3m27s sys) |
11m22s (7m48s sys) |
The
Oracle 11g Performance Tuning guide notes that the multiple buffer pools are
indeed beneficial in I/O reduction, but only under certain circumstances:
With segments that have atypical access
patterns, store blocks from those segments in two different buffer pools:
the KEEP pool and the RECYCLE pool. A segment's access pattern may be
atypical if it is constantly accessed (that is, hot) or infrequently
accessed (for example, a large segment accessed by a batch job only once a
day).
Multiple buffer pools let you address
these differences. You can use a KEEP buffer pool to maintain frequently
accessed segments in the buffer cache, and a RECYCLE buffer pool to prevent
objects from consuming unnecessary space in the cache. . .
By allocating objects to appropriate
buffer pools, you can:
- Reduce or
eliminate I/Os
- Isolate or
limit an object to a separate cache"
Over the years, there have been heated discussions about
the benefits of using multiple blocksizes, especially in these areas:
- Faster performance? - Some claim up to 3x
faster elapsed times with a larger index blocksize. See these
TPC benchmarks that employed multiple blocksizes. Vendors spend
huge sums of money optimizing their systems for TPC benchmarks, so this
indicates that they employed multiple blocksizes for a performance reason.
- Faster updates - In 64-bit database with large
data buffers (over 50 gig), some shops claim a benefit from segregating
high-impact DML tables into a separate blocksize, assigned to a separate,
small buffer. They claim that this improved DML throughput because
there are fewer RAM buffer chains to inspect for dirty blocks.
- Data segregation - Some DBA's use separate 2k
data buffers for tablespaces that randomly fetch small rows, thereby
maximizing RAM by not reading-in more data than required by the query.
Guy Harrison's bestselling book "Oracle SQL
High-Performance Tuning" notes that larger blocksizes can improve the
throughout of full-scan operations:
"The size of the Oracle block can have an influence on the
efficiency of full-table scans. Larger block sizes can often improve scan
performance."
Vendor notes on Oracle multiple
blocksizes
These are many
Oracle TPC benchmarks that thoroughly tested multiple blocksizes
vs. one-size fits all. Because a benchmark is all about maximizing
performance, it appears that these world-record Oracle benchmarks chose multiple
blocksizes because it provided the fastest performance for their hardware. These
benchmarks are fully reproducible, so there performance gains can be proven
independently.
This
UNISYS Oracle benchmark used multiple blocksizes to achieve
optimal performance"
db_cache_size = 4000M
db_recycle_cache_size = 500M
db_8k_cache_size = 200M
db_16k_cache_size = 4056M
db_2k_cache_size = 35430M
The IBM Oracle Technical Brief titled "Oracle
Architecture and Tuning on AIX" (November 2006) notes that careful
evaluation is required before implementing multiple blocksizes:
While most customers only use the default database
block size, it is possible to use up to 5 different database block sizes for
different objects within the same database.
Having multiple database block sizes adds
administrative complexity and (if poorly designed and implemented) can have
adverse performance consequences. Therefore, using multiple block sizes
should only be done after careful planning and performance evaluation.
The paper continues with specific examples of differing I/O
patterns that are related to the database blocksize:
Some possible block size considerations are as follows:
- Tables with a relatively small row size that are
predominantly accessed 1 row at a time may benefit from a smaller
DB_BLOCK_SIZE, which requires a smaller I/O transfer size to move a
block between disk and memory, takes up less memory per block and can
potentially reduce block contention.
- Similarly, indexes (with small index entries)
that are predominantly accessed via a matching key may benefit from a
smaller DB_BLOCK_SIZE.
- Tables with a large row size may benefit from a
large DB_BLOCK_SIZE. A larger DB_BLOCK_SIZE may allow the entire row to
fit within a block and/or reduce the amount of wasted space within the
block. Tables or indexes that are accessed sequentially may
benefit from a larger DB_BLOCK_SIZE, because a larger block size results
in a larger I/O transfer size and allows data to be read more
efficiently.
- Tables or indexes with a high locality of
reference (the probability that once a particular row/entry has been
accessed, a nearby row/entry will subsequently be accessed) may benefit
from a larger DB_BLOCK_SIZE, since the larger the size of the block, the
more likely the nearby row/entry will be on the same block that was
already read into database cache.
But what is Oracle's official position on multiple
blocksizes. For Oracle metal-level customers we have the Oracle MOSC
system which provides the official position of Oracle's own experts.
MOSC Note: 46757.1 titled "Notes
on Choosing an Optimal DB BLOCK SIZE" says that there are some benefits from
having larger blocksizes, but only under specific criteria (paraphrased from
MOSC):
-
Large blocks gives more data transfer per I/O call.
-
Larger blocksizes provides less fragmentation (row
chaining and row migration) of large objects (LOB, BLOB, CLOB)
-
Indexes like big blocks because index height can be
lower and more space exists within the index branch nodes.
-
Moving indexes to a larger blocksize saves disk
space. Oracle says "you will conserve about 4% of data storage (4GB
on every 100GB) for every large index in your database by moving from a 2KB
database block size to an 8KB database block size."
MOSC goes on to say that multiple blocksizes may
benefit shops that have "mixed" block size requirements:
What can you do if you have mixed requirements of the
above block sizes?
Oracle9i "Multiple Block Sizes" new feature comes into
the rescue here, it allows the same database to have multiple block sizes at
the same time . . . "
In the IOUG 2005 conference proceeding titled "OMBDB:
An Innovative Paradigm for Data Warehousing Architectures", Anthony D.
Noriega notes evidence that his databases benefited greatly from employing
multiple blocksizes and notes that multiple blocksizes are commonly used in
large databases with limited RAM resources, in applications such as marketing,
advertisement, finance, pharmaceutical, document management, manufacturing,
inventory control, and entertainment industry:
"The paper and presentation will discuss how to best
utilize multiple block size databases in conjunction with table partitioning
and related techniques, . . .
Utilizing Oracle multiblock databases in data
warehousing based systems will prove in the long-term to be a reliable
methodology to approach the diversity of information and related business
intelligence applications processes when integrating existing systems,
consolidating older systems with existing or newly created ones, to avoid
redundancy and lower costs of operations, among other factors.
The input received from those already using multiblock
databases in highly satisfactory in areas such as marketing, advertisement,
finance, pharmaceutical, document management, manufacturing, inventory
control, and entertainment industry."
Next, let's examine the possible benefits of using multiple blocksizes in
large environments.
A simple example of Oracle with
multiple blocksizes
Let's consider an OLTP database with these characteristics:
- The vast majority of text rows are small, say 80
bytes. A 2k blocksize would reduce the waste from reading-in a 8k
block, only to fetch 80 bytes.
- The database is 100 gigabytes, but there is only 8
gigabytes of available data buffers.
- The database stores images (BLOB, CLOB) in a separate
tablespace, requiring a large blocksize to avoid fragmentation.
- The database is heavily indexed, and index access
patterns tend to read large sections of the index.
- The data has a typical usage skew, with some popular
rows, and some rows that are rarely accessed.

A typical database has popular blocks and
unpopular blocks
In this simple example we see the mixed I/O patterns as
described in MOSC.
We know that we need a 16k blocksize to keep our CLOB data
from fragmenting, and we do not want the buffer wastage that occurs when we
read-in a 32k block just to access an 80 byte row.
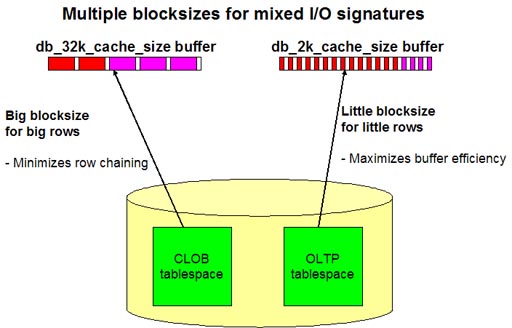
Below, we see a simple illustration to show that small
blocksizes provide a lower-level of data granularity, allowing more
frequently-referenced rows to remain in the RAM buffer:

Smaller blocks reduce wastage when reading small rows
As we see from this illustration, the smaller blocksizes
allow for more hot rows to remain cached within the data buffers. Next
lets see how the relative size of the database size to the data buffer size
influences the choice to try-out multiple blocksizes.
Size Matters!
Also note that the overall percentage of cache is an
influence in the choice to deploy multiple blocksizes. In a large database
with a tiny percentage of RAM, the DBA may want to maximize the efficiency of
the buffers:
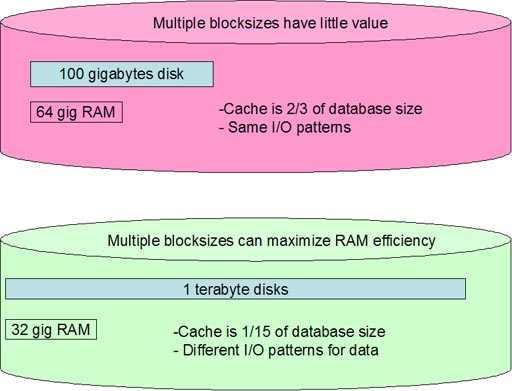
Large databases with limited RAM and varying I/O patterns may find a
greater benefit to multiple blocksizes
Of course, as RAM becomes cheaper and more shops move-away from spinning
platter disks into solid-state Oracle, this will become a moot issue. For
details, see the book "Oracle
disk I/O tuning with SSD".
Let's explore this important Oracle performance issue, and see if we can find
consensus.
Real world experiences with large index
blocksizes
There are numerous reports by end-users who have enjoyed a
benefit from larger blocksizes for indexes, but many experts disagree on the
benefits. While some fervently says that blocksize will not effect
performance, several credible sources note a positive experience with large
blocksizes
-
Bert Scalzo notes that the blocksize made a huge performance
difference in his benchmark tests:
"The larger block size yielded improvements to the load (almost 32%) with no
detriment to the TPS.
In fact,
the TPS improved over 2%. But notice that we have reached a critical
juncture in block size increases.
The load time improvement decreased quite significantly--138% to 32%--and
the TPS gain was nearly three times as much as that of the 4K block size."
-
Todd Boss (an Oracle DBA in
Washington DC) notes significant response time differences between Oracle block
sizes in controlled tests:
We've recently done similar tests to diagnose some I/O
issues and discovered the following (details of test: 100,000 inserts,
committing after every record, then dropping the table).
- Insert activity was almost identical in a 2k versus
8k server.
- Insert activity took about 100% longer in a 32k
server (inserting to a 32k tablespace).
- Insert activity took about 1300% longer when the 32k
server tried to insert to a 2k tablespace ... 40 seconds versus 9 minutes.
- Disks using Volume Manager outperformed plain file
systems by 400% (14 seconds versus 42 seconds).
Matching my block size to my filesystem size (8k on
Solaris in my case) did nothing to help the inserts, but strangely made the
"drop table" run 5 times as fast. Can anyone explain that?
My short answer to the original question posed (what
db_block_size should I pick) would be this:
- Heavy OLTP: 2k block size (but must be a high
contention ... not just inserts)
- Heavy Data Warehouse/DSS: 32k block size
- *Any* other activity; go with standard block size for
your OS (8k on unix, 4k on Windows boxes)."
-
M. J.
Schwenger notes that his shop had experienced good results with larger
blocksizes for their indexes:
"I have used in the past 32K blocksize for indexes to
improve performance and had very good results."
-
Balkrishan Mittal
noted a performance problem when he switched his indexes to a smaller blocksize:
"when I transferred my index tablespace to 8k block
size from 4k blocksize i got some negative results. My servers CPU
usage went to 100% (all the time)
After bearing it for two days i again restored my index tablespace to 4k
block size and CPU usage is again now at 15 - 25%"
- David
Aldridge
notes a
test
where is noted a 6% reduction with larger index blocksizes, a significant
difference, especially to larger shops :
"there are multiple stages in deciding whether the
larger block size is beneficial to a system ...
-
Working out what low level operations benefit from
it (multi-block reads, single block reads)
-
Identifying what higher-level access methods make
use of these operations
-
Applying this to the type of object (table/index)
and system type (reporting/OLTP)"
-
Chris Foot
(Oracle ACE and senior
database architect) notes that employing multiple block sizes can help
maximize I/O performance: "
"Multiple blocksize specifications allow administrators
to tailor physical storage specifications to a data objects size and usage
to maximize I/O performance."
-
Santosh Kumar notes a significant response time reduction after a move to a
larger blocksize: "where a user has given example of the response time of
the same query from two databases, one was having standard block size of 8k and
other one was having 16k:
set timing on
SQL> r
1 select count(MYFIELD) from table_8K where ttime >to_date('27/09/2006','dd/mm/y
2* and ttime <to_date('06/10/2006','dd/mm/yyyy')
COUNT(MYFIELD)
-------------------
164864
Elapsed: 00:00:01.40
...
(This command is executed several times - the execution time was
approximately the same ~
00:00:01.40)
And now the test with the same table, but created together with the index in
16k tablespace:
SQL> r
1 select count(MYFIELD) from table_16K where ttime >to_date('27/09/2006','dd/mm/
2* and ttime <to_date('06/10/2006','dd/mm/yyyy')
COUNT(MYFIELD)
-------------------
164864
Elapsed: 00:00:00.36
(Again, the command is executed several times, the new execution time is
approximately the same ~
00:00:00.36 )
-
Steve Taylor, the
Technical Services Manager for Eagle Investment Systems Corporation
notes a significant I/O reduction:
My favourite recent article was
on 32KB indexes - Our client (200GB+) saw a 20% reduction in I/O from this
simple change...
The server had 8 CPUs 32gb RAM with db_cache_size =
3g and db_32k_cache_size = 500mb. The database was over 200 gigabytes.
Are multiple blocksizes right for my
database?
Every database is unique, and all prudent DBA's will test
changes to standard blocksizes with a representative test using a real-world
workload.
Remember, multiple blocksizes are not for everyone, and you
need to carefully check to see if your database will benefit by performing a
statistically valid workload test in your QA instance.
Most shops will use tools such as the Oracle benchmark
factory or the Oracle 10g SQL tuning Sets (STS) to capture and replay a
representative workload. See the book "Database
Benchmarking" for complete details on best practices for SGA changes.
Also, note the new
11g SQL performance analyzer (SPA) which can be used to test changes to any
init.ora settings.
My related multiple blocksize notes
See my related notes on Oracle multiple blocksizes:


