 |
|
Oracle Multiple blocksize tips
Oracle Tips by Burleson Consulting |
Note: Oracle
is constantly in flux. For the latest on using multiple blocksizes in Oracle, see
The latest consensus on
multiple blocksizes. Also note that
empirical evidence suggests that you can use the
large (16-32K) blocksize and separate data caches to improve response
time under certain conditions. Finally, see how an
Oracle tuning Guru achieves 20x performance improvement by
changing blocksizes.
WARNING: Using
multiple blocksizes effectively is not simple. It requires
expert-level Oracle skills and an intimate knowledge of your I/O
landscape. While deploying multiple blocksizes can greatly
reduce I/O and improve response time, it can also wreak havoc in the
hands of inexperienced DBA's. Using non-standard blocksizes is
not recommended for beginners.
Databases with multiple blocksizes have been around for more than 20
years and were first introduced in the 1980's as a method to
segregate and partition data buffers. Once Oracle adopted
multiple blocksizes in Oraclein 2001, the database foundation for
using multiple blocksizes was already as well-tested and proven
approach. Non-relational databases such as the CA IDMS/R network
database have been using multiple blocksizes for nearly two decades.
All else being equal, insert-intensive databases
will perform less write I/O (via the DBWR process) with larger block sizes
because more "logical inserts" can take place within the data buffer before the
block becomes full and requires writing it back to disk.
At first, beginners denounced multiple block sizes because they were invented to
support transportable tablespaces. Fortunately, Oracle has codified the
benefits of multiple blocksizes, and the
Oracle 11g Performance Tuning Guide notes that multiple blocksizes are
indeed beneficial in large databases to eliminate superfluous I/O and isolate
critical objects into a separate data buffer cache:
'With segments that have atypical
access patterns, store blocks from those segments in two different buffer
pools: the KEEP pool and the RECYCLE pool.
A segment's access pattern may be
atypical if it is constantly accessed (that is, hot) or infrequently
accessed (for example, a large segment accessed by a batch job only once a
day).
Multiple buffer pools let you address
these differences. You can use a KEEP buffer pool to maintain frequently
accessed segments in the buffer cache, and a RECYCLE buffer pool to prevent
objects from consuming unnecessary space in the cache. . .
By allocating objects to appropriate
buffer pools, you can:
- Reduce or
eliminate I/Os
- Isolate or
limit an object to a separate cache"
Let's review the benefits of using
multiple block sizes.
Our experience with different blocksizes
BC has seen dozens of cases where changing the blocksize can have a profound
impact on overall performance, both in response time and throughput performance,
and the choice of blocksize is one of the most important tuning considerations.
BC recently had a server running Oracle 9.2.0.8. Two instances on the
machine, each with the EXACT same parameters except for DB_BLOCK_SIZE, all files
located on the EXACT same mounts.
When the 16k instance runs an 850,000 row update (no where clause), it finishes
in 45 minutes. When the 4k instance runs an 850,000 row update (no where
clause), it finishes in 2.2 minutes. The change in blocksize caused the job to
run TWENTY TIMES FASTER.
A client has an update that they must run (unfortunately) which updates
~830,000 rows, setting one column equal to the other (two column table). On
their development environment this was taking roughly twenty seconds to perform.
However, on their soon-to-be production environment it was taking roughly 45
minutes.
Explain plans were checked, trace files examined, and not much popped up
except that the production machine was attempting larger I/Os during the update
and was consequently taking much longer. Comparing the initialization parameters
between production and development showed the exact same parameters, except that
the upcoming production box was using a 16k block size and development was using
a 4k block size.
The final result: When the update was run against the 16k blocksize DB, it
took 45 minutes. Against the 4k blocksize DB on the same box with the same
parameters and the same FS mounts, it took 2 minutes 20 seconds.
I even took it a step further to see if we could squeeze any more performance
out of it. Setting FILESYSTEMIO_OPTIONS='SETALL' (instead of none) I was able to
get the update down to 1.5 minutes. Turning off DB_BLOCK_CHECKING (not
recommended) I was able to get it down to 10 seconds.
By going from a 16k blocksize to a 4k blocksize with all other things being
equal, we experienced roughly a twenty times improvement. We shaved off even
more time setting FILESYSTEMIO_OPTIONS = SETALL. And then we changed
DB_BLOCK_CHECKING, a parameter Oracle documentation says only adds a 1 to 10%
overhead depending on concurrency of DML, which made the update 6 times faster
alone.
The final result was a 270 times improvement over the original, changing only
the db_block_size. To be fair, I also tried setting the
FILESYSTEMIO_OPTIONS and DB_BLOCK_CHECKING the same on the 16k blocksize
instance, which resulted in the update taking 30 minutes as opposed to 45. The
results were better, but the 4k blocksize database still won by 180 times.
What's more, all queries both large and small performed the same or better
than in production, and a test insert of 100,000 rows went from 20 seconds on
the 16k blocksize to 3 seconds on the 4k.
While this experiment definitely shows that changing only blocksize can have
a profound effect, more thorough analysis will help get to the core of why
changing blocksizes had such a positive tuning effect.
The benefits of a larger blocksize
The benefits of large blocksizes are demonstrated on this
OTN thread where we see a demo showing 3x faster performance using a larger
block size:
SQL> r
1 select count(MYFIELD) from table_8K where ttime
>to_date('27/09/2006','dd/mm/y
2* and ttime <to_date('06/10/2006','dd/mm/yyyy')
COUNT(MYFIELD)
-------------------
164864
Elapsed: 00:00:01.40
...
(This command is executed several times - the execution
time was approximately the same ~
00:00:01.40)
And now the test with the same table, but created together with the index in
16k tablespace:
SQL> r
1 select count(MYFIELD) from table_16K where ttime
>to_date('27/09/2006','dd/mm/
2* and ttime <to_date('06/10/2006','dd/mm/yyyy')
COUNT(MYFIELD)
-------------------
164864
Elapsed: 00:00:00.36
(Again, the command is executed several times, the new
execution time is approximately the same ~
Oracle consultant Ben Prusinski notes that batch jobs can see a 3x
performance improvement when moved to a larger blocksize:
"My experiences have been that using different block sizes can make a
difference.
For a past customer a large financial company, we improved database
performance by increasing block size from 8k blocksize to 16k blocksize.
Performance for nightly data loads went down from 22 hours to 6 hours when
we increased the database block size."
It's interesting that Oracle introduced multiple blocksizes while
not realizing their full potential. Originally implemented to
support transportable tablespaces, Oracle DBA's quickly realized the
huge benefit of multiple blocksizes for improving the utilization
and performance of Oracle systems.
These benefits fall into
several general areas:
Reducing data buffer waste
By performing block reads of an appropriate size the DBA can
significantly increase the efficiency of the data buffers. For
example, consider an OLTP database that randomly reads 80 byte
customer rows. If you have a 16k db_block_size, Oracle
must read all of the 16k into the data buffer to get your 80 bytes,
a waste of data buffer resources. If we migrate this customer
table into a 2k blocksize, we now only need to read-in 2k to get the
row data. This results in 8 times more available space for
random block fetches.

Improvements in data buffer utilization
Reducing logical I/O
As more and more Oracle database become CPU-bound as a result of
solid-state disks and 64-bit systems with large data buffer caches,
minimizing logical I/O consistent gets from the data buffer) has
become an important way to reduce CPU consumption. This can be
illustrated with indexes. Oracle performs index range scams
during many types of operations such as nested loop joins and
enforcing row order for result sets. In these cases, moving
Oracle indexes into large blocksizes can reduce both the physical
I/O (disk reads) and the logical I/O (buffer gets).
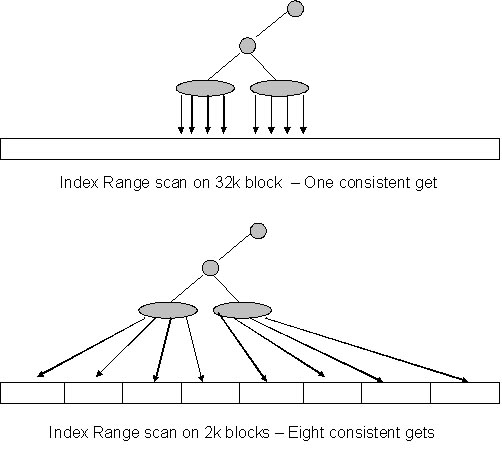
Robin Schumacher has proven in his book
Oracle
Performance Troubleshooting (2003, Rampant TechPress)
that Oracle b-tree indexes are built in flatter structures in 32k
blocksizes. We also see a huge reduction in logical I/O during
index range scans and sorting within the TEMP tablespace because
adjacent rows are located inside the same data block.
We can also identify those indexes
with the most index range scans with this simple AWR script.
col c1 heading 'Object|Name' format a30
col c2 heading 'Option' format a15
col c3 heading 'Index|Usage|Count' format 999,999
select
p.object_name c1,
p.options c2,
count(1) c3
from
dba_hist_sql_plan p,
dba_hist_sqlstat s
where
p.object_owner <> 'SYS'
and
p.options like '%RANGE SCAN%'
and
p.operation like '%INDEX%'
and
p.sql_id = s.sql_id
group by
p.object_name,
p.operation,
p.options
order by
1,2,3;
Here is the output where we see
overall total counts for each object and table access method.
Index
Object
Usage
Name
Option
Count
----------------------------- --------------- --------
CUSTOMER_CHECK RANGE SCAN
4,232
AVAILABILITY_PRIMARY_KEY RANGE
SCAN 1,783
CON_UK
RANGE SCAN
473
CURRENT_SEVERITY
RANGE SCAN
323
CWM$CUBEDIMENSIONUSE_IDX RANGE
SCAN
72
ORDERS_FK
RANGE SCAN
20
Improving data buffer efficiency
One of the greatest problems if very large data buffers is the
overhead of Oracle in cleaning-out 'direct blocks' that result from
truncate operations and high activity DML. This overhead can
drive-up CPU consumption of databases that have large data buffers.

Dirty Block cleanup in a large vs. small data buffer
By segregating high activity tables into a separate, smaller data
buffer, Oracle has far less RAM frames to scan for dirty block,
improving the throughout and also reducing CPU consumption.
This is especially important for super-high update tables with more
than 100 row changes per second.
Improving SQL execution plans
It's obvious that intelligent buffer segregation improves overall
execution speed by reducing buffer gets, but there are also some
other important reasons to use multiple blocksizes.
In general, the Oracle cost-based optimizer is unaware of buffers
details (except when you set the optimizer_index_caching
parameter), and using multiple data buffers will not impact SQL
execution plans. When data using the new cpu_cost
parameter in Oracle10g, the Oracle SQL optimizer builds the SQL plan
decision tree based on the execution plan that will have the lowest
estimated CPU cost.
For example, if you implement a 32k data buffer for your index
tablespaces you can ensure that your indexes are caches for optimal
performance and minimal logical I/O in range scans.
For example, if my database has 50 gigabytes of index space, I can
define a 60 gigabyte db_32k_cache_size and then set my
optimizer_index_caching parameter to 100, telling the SQL
optimizer that all of my Oracle indexes reside in RAM.
Remember when Oracle makes the index vs. table scan decision,
knowing that the index nodes are in RAM will greatly influence the
optimizer because the CBO knows that a logical I/O is often 100
times faster than a physical disk read.
In sum, moving Oracle indexes into a fully-cached 32k buffer will
ensure that Oracle favors index access, reducing unnecessary
full-table scans and greatly reducing logical I/O because adjacent
index nodes will reside within the larger, 32k block.
Real World Applications of multiple
blocksizes
The use of multiple blocksizes is the most important for very-large
database with thousands of updates per second and thousands of
concurrent user's access terabytes of data. In these
super-large databases, multiple blocksizes have proven to make a
huge difference in response time.
Largest Benefit:
We wee the largest benefit of multiple blocksizes in these types of
databases:
Smallest benefit:
However, there are specific types of databases that may not benefit
from using multiple blocksizes:
-
Decision Support Systems
- Large Oracle
data warehouses with parallel large-table full table scans do not
benefit from multiple blocksizes. Remember, parallel
full-table scans bypass the data buffers and store the
intermediate rows sets in the PGA region. As a general rule,
databases with the
all_rows optimizer_mode may not benefit from multiple
blocksizes.
Even though Oracle introduced multiple blocksizes for a innocuous
reason, their power has become obvious in very large database
systems. The same divide-and-conquer approach that Oracle has
used to support very large databases can also be used to divide and
conquer your Oracle data buffers.
Setting your db_block_size with multiple block
sizes
When you implement multiple
blocksizes you should set your db_block_size based on the
size of the tablespace where your large-object full-scans will be
occurring. Remember, the parameter db_file_multiblock_read_count
is only applicable for tables/indexes that are full scanned.
|
 |
Tip:
Objects that experience full-table scans should
be placed in a larger block size, with
db_file_multiblock_read_count set to the block size of that
tablespace. |
When you implement multiple blocksizes, Oracle MOSC notes that
you should always set your db_file_multiblock_read_count to a
common value, normally your largest supported blocksize of 32k:
db_block_size
db_file_multiblock_read_count
2k
16
4k
8
8k
4
16k
2
Oracle MOSC
Note:223299.1 also embraces the
importance of multiple blocksizes, listing the multiple buffer
regions as among the most important tuning parameters in Oracle.
According to Oracle, this is the formula for setting
db_file_multiblock_read_count:
max I/O chunk size
db_file_multiblock_read_count = -------------------
db_block_size
But what is our maximum I/O chunk size? The maximum effective setting for
db_file_multiblock_read_count is OS and disk dependant. Steve
Adams, an independent Oracle performance consultant (see
www.ixora.com.au ), has
published a helpful script to assist you in setting an appropriate
level.
http://www.ixora.com.au/scripts/sql/multiblock_read_test.sql

The Ion tool is
the easiest way to analyze STATSPACK disk I/O data in Oracle and Ion
allows you to spot hidden I/O trends.


