|
 |
|
Oracle dbms_stats tips
Oracle Database Tips by Donald Burleson |
Prior to Oracle 10g, adjusting
optimizer parameters was the only way to compensate for sample size
issues with dbms_stats. As of 10g, the use of
dbms_stats.gather_system_stats and improved sampling within
dbms_stats had made adjustments to these parameters far less
important. Ceteris Parabus, always adjust CBO statistics before
adjusting optimizer parms. For more details on optimizer
parameters, see my latest book "Oracle
Tuning: The Definitive Reference".
As a review, the CBO gathers information from many sources, and he has
the lofty goal of using DBA-provided metadata to always make the "best"
execution plan decision:
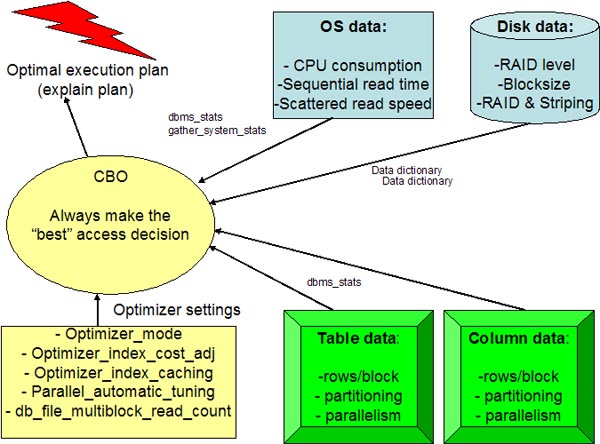
Oracle uses data
from many sources to make an execution plan
Let's examine the following areas of CBO
statistics and see how to gather top-quality statistics for the CBO
and how to create an appropriate CBO environment for your database.
Getting top-quality statistics for the
CBO. The choices of executions plans
made by the CBO are only as good as the statistics available to it.
The old-fashioned analyze table
and dbms_utility methods for
generating CBO statistics are obsolete and somewhat dangerous to SQL
performance. As we may know, the CBO uses object statistics to choose
the best execution plan for all SQL statements.
The
dbms_stats
utility does a far better job in estimating statistics, especially for
large partitioned tables, and the better statistics result in faster
SQL execution plans. Here is a sample execution of
dbms_stats with the OPTIONS
clause:
exec dbms_stats.gather_schema_stats( -
ownname => 'SCOTT', -
options => 'GATHER AUTO', -
estimate_percent => dbms_stats.auto_sample_size, -
method_opt => 'for all columns size repeat', -
degree => 34 -
)
Here is another dbms_stats example that creates histograms on all indexes columns:
BEGIN
dbms_stats.gather_schema_stats(
ownname=>'TPCC',
METHOD_OPT=>'FOR ALL INDEXED COLUMNS SIZE SKEWONLY',
CASCADE=>TRUE,
ESTIMATE_PERCENT=>100);
END;
/
There are several values for the
OPTIONS parameter that we need to know
about:
- GATHER_ reanalyzes the
whole schema
- GATHER EMPTY_ only
analyzes tables that have no existing statistics
- GATHER STALE_ only
reanalyzes tables with more than 10 percent modifications (inserts,
updates, deletes)
- GATHER AUTO_ will
reanalyze objects that currently have no statistics and objects with
stale statistics. Using GATHER AUTO
is like combining GATHER STALE
and GATHER EMPTY.
Note that both
GATHER STALE
and GATHER AUTO require
monitoring. If you issue the ALTER TABLE XXX MONITORING
command, Oracle tracks changed tables with the
dba_tab_modifications view. Below we see
that the exact number of inserts, updates and deletes are tracked
since the last analysis of statistics:
SQL> desc dba_tab_modifications;
Name Type
--------------------------------
TABLE_OWNER VARCHAR2(30)
TABLE_NAME VARCHAR2(30)
PARTITION_NAME VARCHAR2(30)
SUBPARTITION_NAME VARCHAR2(30)
INSERTS NUMBER
UPDATES NUMBER
DELETES NUMBER
TIMESTAMP DATE
TRUNCATED VARCHAR2(3)
The most interesting of these options is the
GATHER STALE option. Because
all statistics will become stale quickly in a robust OLTP database, we
must remember the rule for GATHER STALE
is > 10% row change (based on num_rows
at statistics collection time). Hence, almost every table except
read-only tables will be reanalyzed with the GATHER STALE
option, making the GATHER STALE
option best for systems that are largely read-only. For example, if
only five percent of the database tables get significant updates, then
only five percent of the tables will be reanalyzed with the
GATHER STALE option.
Automating sample size with
dbms_stats.The better the quality
of the statistics, the better the job that the CBO will do when
determining your execution plans. Unfortunately, doing a complete
analysis on a large database could take days, and most shops must
sample your database to get CBO statistics. The goal is to take a
large enough sample of the database to provide top-quality data for
the CBO.
Now that we see how the
dbms_stats option works, let's see how to
specify an adequate sample size for dbms_stats.
In earlier releases, the DBA had to guess
what percentage of the database provided the best sample size and
sometimes under-analyzed the schema. Starting with Oracle9i
Database, the estimate_percent
argument is a great way to allow Oracle's dbms_stats
to automatically estimate the "best" percentage of a segment to sample
when gathering statistics:
estimate_percent => dbms_stats.auto_sample_size
Andrew Holdsworth
of Oracle Corporation notes that dbms_stats is essential to
good SQL performance, and it should always be used before adjusting
any of the Oracle optimizer initialization parameters:
"The payback
from good statistics management and execution plans will exceed
any benefit of init.ora tuning by orders of magnitude"
Export Import statistics
with dbms_statsYou can use the Oracle dbms_stats and export
utilities to migrate schema statistics from your PROD instance to
your TEST instance, so that your developers will be able to do
more-realistic execution-plan tuning of new SQL before it's migrated
into PROD. Here are the steps:
Step 1: Create the stats_table:
exec
dbms_stats.create_stat_table(ownname => 'SYS', stattab => 'prod_stats',
- >
tblspace => 'SYSTEM');
Step 2: Gather the statistics with
gather_system_stats. In this dbms_stats example, we compute
histograms on all indexed columns:
DBMS_STATS.gather_schema_stats(
ownname=>'<schema>',
estimate_percent=>dbms_stats.auto_sample_size
cascade=>TRUE,
method_opt=>'FOR ALL COLUMNS SIZE AUTO')
Step 3: Export the stats to the
prod_stats table using export_system_stats::
exec
dbms_stats.export_system_stats(ownname => 'SYS', stattab => 'prod_stats');
Step 4: Export the stats to the
prod_stats table using exp:
exp scott/tiger
file=prod_stats.dmp log=stats.log tables=prod_stats
rows=yes
Step 5: FTP to the production server:
ftp -i
prodserv . . .
Step 6: Import the stats from the
prod_stats.dmp table using the import (imp) utility:
imp scott/tiger
file=prod_stats.dmp log=stats.log tables=prod_stats
rows=yes
Step 7: We can now use the
import_system_stats procedure in Oracle dbms_stats to overlay the existing
CBO statistics from the smaller TEST instance:
dbms_stats.import_system_stats('STATS_TO_MOVE');
Arup Nanda has a great article on extended statistics with dbms_stats,
specialty histogram analysis using function-based columnar data:
Next, re-gather statistics on the table and collect the
extended statistics on the expression upper(cust_name).
begin
dbms_stats.gather_table_stats (
ownname => 'ARUP',
tabname => 'CUSTOMERS',
method_opt => 'for all columns size skewonly for columns (upper(cust_name))'
);
end;
Alternatively you can define
the column group as part of the gather statistics command.
You do that by placing
these columns in the method_opt parameter of the gather_table_stats procedure in
dbms_stats as shown below:
begin
dbms_stats.gather_table_stats (
ownname => 'ARUP',
tabname => 'BOOKINGS',
estimate_percent=> 100,
method_opt => 'FOR ALL COLUMNS SIZE SKEWONLY FOR COLUMNS(HOTEL_ID,RATE_CATEGORY)',
cascade => true
For more details, see these notes on
11g
extended optimizer statistics.This advice from the Oracle
Real-world tuning group:
>> Will dbms_stats someday detect sub-optimal table join orders from a workload,
and create appropriate histograms?
If histograms exist, then they were either automatically created because the
columns met the criteria defined on page 10-11 of the document, or manually
created. If they were created automatically, then is probable they will
influence the plan for the better.
Sub-optimal join orders are generally the result of poor cardinality estimates.
Histograms are designed to help with cardinality estimates where data skew
exists.
>> Keeping statistics: What is the current "official" policy regarding statistics retention? The old CW was that the DBA should collect a deep, representative sample, and
keep it, only re-analyzing when it's "a difference that makes a difference"?
I don't know if there is an "official" policy per se, but I will offer my
professional opinion based on experience. Start with the dbms_stats defaults.
Modify as necessary based on plan performance. Use dynamic sampling and/or
dbms_sqltune or hints/outlines where appropriate (probably in that order).
Understand the problem before attempting solutions.
There are a couple of cases that I would be mindful of:
1) Experience has shown that poor plans can be a result of under estimated NDV
with skewed data and DBMS_STATS.AUTO_SAMPLE_SIZE
(or too small of a sample). This has been addressed/enhanced in 11g. In 10g it
requires choosing a fixed sample size that yields an accurate enough NDV to get
the optimal plan(s). The sample size will vary case by case as it is data
dependent.
2) Low/High value issues on recently populated data, specifically with
partitioned tables. If the partition granule size is small (say daily or
smaller) the default 10% stale might be too little. It may be best to gather
partition stats immediately after loading, or set them manually. It's better to
have stats that are an over estimate on the number of rows/values than an under
estimate. For example, its better to have a hash join on a small set of data
than a nested loops on a large set.
 |
|
Get the Complete
Oracle SQL Tuning Information
The landmark book
"Advanced Oracle
SQL Tuning The Definitive Reference" is
filled with valuable information on Oracle SQL Tuning.
This book includes scripts and tools to hypercharge Oracle 11g
performance and you can
buy it
for 30% off directly from the publisher.
|
See my related dbms_stats notes:
|


