|
Update: See Oracle 10g sorted hash clusters:
Speed response times the easy way-sequence table rows
to match a primary index.
Experienced Oracle database administrators know that I/O is the single
greatest component of response time. When Oracle retrieves a block from a
data file on disk, the reading process must wait for the physical I/O
operation to complete. Consequently, anything you can do to minimize
I/O-or reduce bottlenecks caused by contention for files on disk-can
greatly improve the performance of an Oracle system. One way to avoid
bottlenecks is to spread the data files across the server's hard-disk
drives so that no single file (or set of files) becomes a hot spot and,
potentially, a bottleneck. By moving high-activity files to less-active
disks, you can prevent or ameliorate disk-I/O bottlenecks.
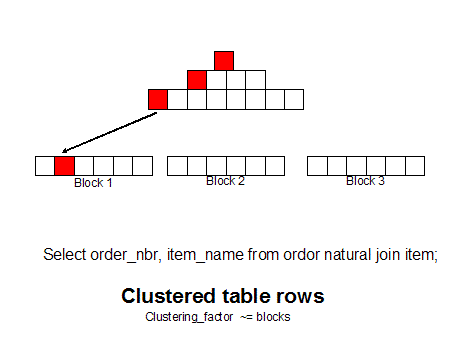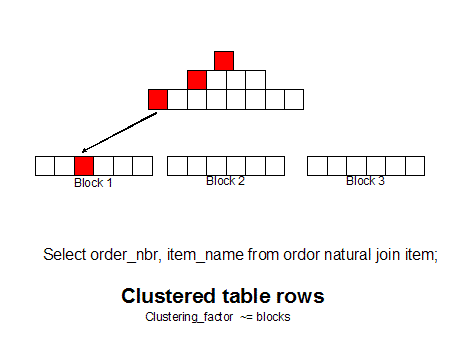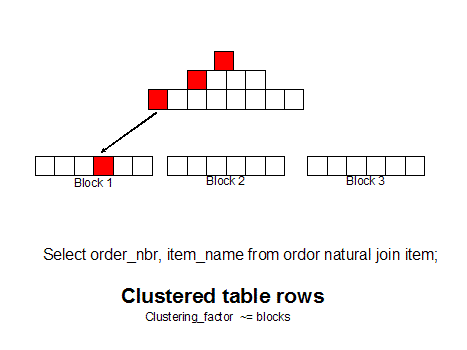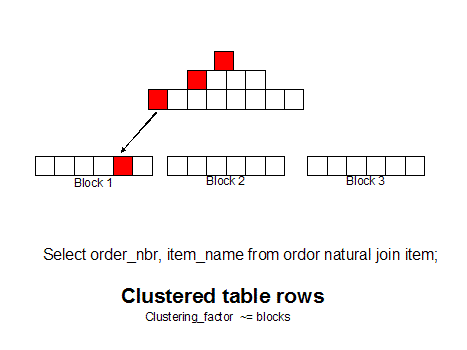
For queries that
access common rows with a table (e.g. get all items in order 123), unordered
tables can experience huge I/O as the index retrieves a separate data block for
each row requested.

If we group like
rows together (as measured by the clustering_factor in dba_indexes) we can get
all of the row with a single block read because the rows are together. You
can use 10g hash cluster tables, single table clusters, or manual row
re-sequencing (CTAS with ORDER BY) to achieve this goal:
To reduce the amount of disk I/O itself, however, you need a way to
ensure that when you retrieve data from the disk, you get what you need
and, ideally, what you'll need next. An easy, low-cost way to do just that
is to employ a technique that involves using the
CREATE TABLE AS
SELECT (CTAS) statement to create a new table based on the primary
order of the existing table's index. In high-volume
online-transaction-processing (OLTP) environments-in which data is
accessed via a primary index-resequencing table rows so that contiguous
blocks follow the same order as their primary index can actually reduce
physical I/O and improve response time during index-driven table queries.
This technique is useful only when the application selects multiple rows,
using index range scans, or if the application issues mulitple requests
for consecutive keys; random primary-key unique accesses won't benefit.
You can use the export/import method to accomplish the same goal, but the
CTAS method has some advantages: Instead of spending hours with the Oracle
EXPORT-IMPORT utilities, CTAS requires only a few simple SQL statements. And
because CTAS is one of the two dozen or so operations that Oracle can execute in
parallel (if you employ the appropriate syntax), it works well for large tables
as well as small ones. The process basically is as follows:
- Create a new table from the old one, using the table's index to establish
the appropriate data sequence.
- Give the old table a different name, and, optionally, store it in a
different tablespace.
- Give the new table the name of the old table.
- Create a new index on the renamed, reorganized table.
To use this technique, you must have a primary index on the table in question
and you must be running Oracle Database Server Release 7.3.4 or later, since the
AS SELECT syntax for
CREATE TABLE wasn't supported before
that.
Will Your System Benefit?
The degree to which resequencing improves performance depends on how far out
of sequence the rows are when you begin and how many rows you will be accessing
in sequence. You can find out how well a table's rows match the index's sequence
key by looking at the DBA_INDEXES and
DBA_TABLES views in the
data dictionary: DBA_INDEXES contains descriptions of all indexes in
the database; DBA_TABLES contains descriptions of all relational tables
in the database.
To gather statistics, you can use the
SQL ANALYZE command.
(Remember, though, that collecting statistics can affect optimizer behavior and
severely degrade a system and that a large table can take some time to analyze.)
If you analyze as SYS, you need to include the index and table owners in the
ANALYZE
command. It's preferable to do the ANALYZE as the schema owner.
In the DBA_INDEXES view, look at the clustering_factor column: If
the clustering factor-an integer-roughly matches the number of blocks in the
table, your table is in sequence with the index order. However, if the
clustering factor is close to the number of rows in the table, it indicates that
the rows in the table are out of sequence with the index.
Two Alternatives
If you determine that your table can benefit from resequencing, you need to
decide which approach to take. You can use the CTAS statement in one of two
ways:
- in conjunction with an
ORDER BY clause
- in conjunction with a hint that identifies the index to use
Basically, the CTAS statement copies the selected portion of the table into a
new table. If you select the entire table with an
ORDER BY clause or an
index hint, it will copy the rows in the same order as the primary index. In
addition to resequencing the rows of the new table, the CTAS statement coalesces
free space and migrated/chained rows and resets free lists, thereby providing additional
performance benefits. You can also alter table parameters, such as initial
extents and the number of free lists, as you create the new table.
The approach you choose depends on the size of the table involved, the
overall processing power of your environment, and how quickly you need to have
the tables back online and available. The details of each approach are discussed
more fully below, but in either case, when you create the new table, you can
speed the process by using the NOLOGGING option (called
UNRECOVERABLE
prior to Oracle8) to skip the added overhead of the redo-log file (back up the
old and new tablespaces).
Using CTAS with the
ORDER BY clause. To use the CTAS
statement with the ORDER BY clause (and a
PARALLEL clause, to
reduce the processing time), structure the CTAS statement as shown in Listing
1. Using this approach without the PARALLEL clause can be very
slow. The database reads the original table quickly (generally in non-index
order) by invoking a full-table scan to retrieve the rows and then performs a
massive sort of the table to resequence the rows before it actually creates the
new table.
The PARALLEL clause causes the CTAS operation to execute on multiple
processes (or multiple threads, in Microsoft Windows NT), which sometimes makes
the ORDER BY approach faster than the index-hint approach. If your
hardware has multiple CPUs and many-perhaps hundreds-of processes, for example,
this approach is likely to be significantly faster. However, if your hardware
configuration has a relatively modest number of processes (such as the four
specified in the example), the index-hint approach is likely to be faster.
Using CTAS with an index hint. With this approach, structure your CTAS
statement as shown in Listing
2. When this statement executes, the database traverses the existing
primary-key index to access the rows for the new table, bypassing the sorting
operation. Most Oracle DBAs choose this method over the
ORDER BY
approach, because the runtime performance of traversing an index is generally
faster than using the PARALLEL clause and then sorting the entire
result set (unless you have a massive amount of processing power). Use
EXPLAIN
PLAN to verify that it is using the correct index.
Because you can't use an index hint with a
PARALLEL clause, the
index-hint approach cannot take advantage of parallel processing to reorganize a
single table. (This is because the Oracle database must perform a full-table
scan to process a query in parallel, whereas the index hint causes the system to
traverse the index and never use a full-table scan.) You can, however, use
parallel processing to reorganize multiple tables simultaneously.
Reorganizing Tables Quickly
Many Oracle DBAs who use the CTAS method choose to place each large table in
a dedicated tablespace (generally with a name that contains the table name),
along with a separate dedicated tablespace for the reorganized copy of the
table. If you reorganize your tables at regular intervals (since adding and
deleting records gradually puts the physical rows further out of sequence with
the index order), you can copy the tables back and forth at each reorganization.
For example, a customer table might reside in tablespace
CUSTOMER_FLIP
until reorganization, when it would move to
CUSTOMER_FLOP; at the next
reorganization, it would move back to CUSTOMER_FLIP.
When you are reorganizing from one tablespace to another, you should always
have a backup copy of the table and a back-out procedure. The original table
remains online for query in cases of data inconsistency, and you never need to
perform a full restore if the table becomes corrupt. The only real cost of this
method is the disk space required to duplicate major reorganized tablespaces.
Listing 3
shows the SQL syntax needed to reorganize a table by copying it from one
tablespace to another and changing the table-storage parameters as needed. In
addition to the CTAS statement (in this example using the index-hint approach), Listing
3 shows the setup preceding the statement and the renaming and
index-creation steps that follow it.
Multiplexing Tables
If you have several tables to reorganize, you can save time by running the
jobs simultaneously, in parallel. (If you have a large enough system, you can
run multiple concurrent CTAS, too.)
When you process the tables in parallel, the total time required to
reorganize all the tables is no more than that for the largest table. For
example, if you need to reorganize 100GB of tables in a single weekend, the
parallel approach is the only way to go.
Processing multiple CTAS jobs simultaneously is not the same as using a
PARALLEL
clause to execute a single CTAS job using multiple processes. In addition,
processing multiple CTAS jobs does not require a
PARALLEL clause in the
CTAS statement, so you can use either the index-hint approach or the
ORDER
BY approach in the CTAS statement.
Listing 4
is a Korn shell script you can use to execute the reorganization script in Listing
3. This script accepts the table name as input, so you can easily call it
from a higher-level script (such as the one in Listing
5) and run the reorganization script multiple times, in parallel, for
different tables. (For further flexibility, you can also modify the script in Listing
3 to accept the number of extents as an input.)
The Low-I/O Way To Go
If response times are lagging in your high-transaction system, reducing disk
I/O is the best way to bring about quick improvement. And when you access tables
in a transaction system exclusively through range scans in primary-key indexes,
reorganizing the tables with the CTAS method should be one of the first
strategies you use to reduce I/O. By physically sequencing the rows in the same
order as the primary-key index, this method can considerably speed up data
retrieval.
Like disk-load balancing, table reorganization is easy, inexpensive, and
relatively quick. With both techniques in your DBA bag of tricks, you'll be well
equipped to shorten response times-often dramatically-in high-I/O systems.
The main goal of an index is to speed the process of finding data. An index
file contains a data value for a specific field in a table and a pointer that
identifies the record that contains a value for that field. In other words, an
index on the last_name field for a table would contain a list of last names and
pointers to specific records-just as an index to a book lists topics and page
numbers to enable readers to access information quickly. When processing a
request, the database can use some or all of the available indexes to
efficiently locate the requested rows. Oracle uses several indexing schemes, but
B-tree indexes are the most common.
Figures
1 and 2 illustrate some of the concepts of a B-tree index. The upper blocks
contain index data that points to lower-level index blocks. The lowest-level
blocks contain every indexed data value and a corresponding row ID used for
locating the actual row of data.
To illustrate how resequencing can reduce response times, consider a table in
which the rows are not in the same sequence as the index. When the index is used
to retrieve a series of rows that are adjacent to each other in the indexed
version of the table, the index tree points to widely scattered locations among
the physical blocks where the row data is stored (see Figure
1). Because the system must access many blocks to retrieve the data, it
requires many I/O operations. If you resequence the table, however, the rows
will match the order of the primary-key index. Thus, the data from adjacent rows
in the indexed table is stored in a single physical location on the disk (see
Figure 2), and I/O is reduced because the system needs to access fewer
blocks in order to retrieve the data.
|
