Question: I have a SQL explain plan (execution plan)
and it shows a cost of 16. What does this cost column mean? Can
I use these costs for SQL tuning?
Answer: No, the cost column in
an execution plan is not a reliable way to judge the real costs of a SQL
statements response time. Many people assume that an execution plan
with a lower cost will run faster than a plan with a higher cost, but this
is not true, especially in-light of the optimizer_mode parameter
setting, which could be set to all_rows, which minimizes resource
consumption, as opposed to first_rows_n, which minimizes response
time. These are very different costs, and not the costs that appear in
the cost column of an explain plan.
The cost column is supposed to be a guess of
the number of single block disk reads required, but it's not very useful for
SQL tuning.
What is the cost column in an explain plan?
Depending on your release and setting for the hidden
parameter
_optimizer_cost_model (cpu or io), the cost is taken from the
cpu_cost and io_cost columns in the plan table (, in turn, estimates from
sys.aux_stats$. The "cost" column is not any particular unit
of measurement, it is a weighted average of the costs derived from the
cost-based decision tree generated when the SQL statement is bring
processed. The cost column is essentially an estimate of the run-time
for a given operation.
In sum, the cost column is not valuable for SQL tuning,
because the "best" execution plan may not be the one with the lowest cost.
As a review, there are dozens of conditions that go
into the costing algorithm of the cost-based optimizer:
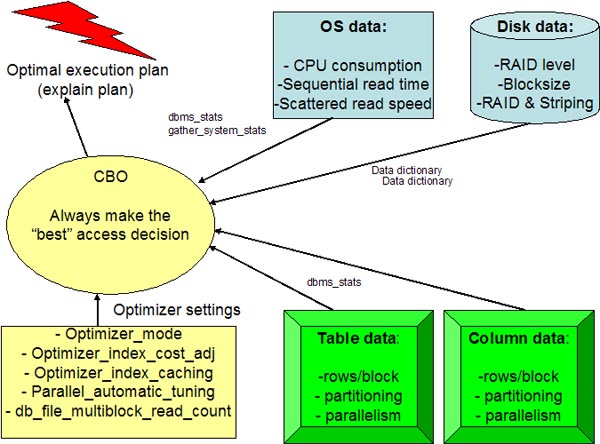
The costing is done via a mathematical model that builds a decision tree,
and Oracle chooses the plan with the lowest cost. However, this
algorithm is constantly changing as Oracle refines their software and you
can only make very general statements about it's behavior.
The
cost-based optimizer was originally written back when disk was
super-expensive and minimizing disk I/O was a major goal in SQL tuning.
Today, of course, many systems use super-fast flash memory (solid-state
disks), and I/O is not so much of an issue. But nonetheless, estimated
disk "costs" are behind the optimizer's estimates of cost.
In the
example below, we see that the optimizer estimates four physical disk reads
to service a nested loops join, and hence we see a cost=4:
--------------------------------------------------------------------
| Id | Operation
| Name | Rows | Bytes | Cost (%CPU)| Time
|
--------------------------------------------------------------------
| 0 | SELECT STATEMENT
| |
1 | 57 | 4 (0)|
00:00:01 |
| 1 |
NESTED LOOPS
| |
1 | 57 | 4 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL
| EMP | 1 |
37 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX
ROWID| DEPT | 1 |
20 | 1 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN
| PK_DEPT | 1 | | 0
(0)| 00:00:01 |
--------------------------------------------------------------------If we estimate this "cost" based on the average sampled I/O latency
(gathered by
dbms_stats.gather_system_stats), we might be able to
estimate the run-time for a query. In this example, assume that our
average disk I/O delay is 15 milliseconds. A "cost" of 4 would mean
that the optimizer expects the query to take roughly 60 milliseconds to
complete.
This feature of the optimizer to do costing in terms of
physical disk reads is one reason why the optimizer buffering parameters
like
optimizer_index_caching are important when tuning a SQL
workload.
The best vs. the cheapest plan
The "cost" figures that are displayed in a SQL execution plan do not
always reflect the "real" costs of a query. Oracle may choose a plan
with a higher cost, depending upon the optimizer's goal (e.g. first_rows vs.
all_rows).
Remember, the "Cost" figures are very misleading and
should not be used as guidelines for SQL tuning for several reasons:
- The optimizers costing can be wrong because of stale or missing
metadata (especially histograms)
- The lowest cost value does not always indicate the "real" lowest
cost that is select by the optimizer.
- In first_rows optimization, extra I/O is required to access the data
via indexes and get the row back quickly. Hence, the optimizer may
choose a more expensive plan because it will return rows faster than a
"cheaper" plan that uses less machine resources.
- Even with complete metadata it is impossible for any optimizer to
always "guess" the accurate size of a result set, especially when
the where clause has complex column calculations.
In other words, Oracle does not always choose the lowest real "cost"
value, and Oracle does not disclose the exact behavior of their optimizer, a
prized competitive edge over other competing databases.
For
example, consider a million row table that takes 30 seconds to full scan.
Now consider a SQL that returns 10,000 rows in sorted order via a index
where clustering_factor approaches num_rows, and two possible execution
plans:
- OPTION 1 - Do an index scan - More I/O (and cost)
to traverse the index top pull the rows in sorted order, but the query
starts delivering rows immediately.
- OPTION 2 - Do a full table scan and back-end sort - his may involve far less work (and less cost), but we will not see any
results for 30 seconds
See, in this example, the optimizer cannot always assume that the least
cost plan is the "best" plan when optimizing for fast response time.
 |
|
Get the Complete
Oracle SQL Tuning Information
The landmark book
"Advanced Oracle
SQL Tuning The Definitive Reference" is
filled with valuable information on Oracle SQL Tuning.
This book includes scripts and tools to hypercharge Oracle 11g
performance and you can
buy it
for 30% off directly from the publisher.
|


