 |
|
SQL to compare rows within two tables
Oracle Database Tips by Donald Burleson |
Oracle Corporation's developer Vadim Tropashko has some
interesting notes on tuning Oracle SQL queries that compare the contents of two
tables, showing several SQL solutions and their performance within the Oracle
cost-based optimizer.
Vadim Tropashko's is the author
of "SQL
Design Patterns: The Expert Guide to SQL Programming", the definitive
reference for SQL design patterns, a critical knowledge area for any Oracle
developer.
Vadim also shows a great example of using the hidden parameter
_convert_set_to_join to improve SQL execution speed for queries that find
the semantic difference between two tables, and he shows how to compare the rows
and columns of two tables with Oracle SQL syntax.
(Note: Hidden parameters are extremely powerful and you
should always thoroughly test all use of hidden SQL tuning parameters and
only use hidden parms like _coinvert_set_to_join at the direction of Oracle
technical support).
Vadim Tropashko's new book "SQL
Design Patterns: The Expert Guide to SQL Programming", is the very first
book to apply the mathematical foundation of SQL in-terms of design patterns, a
must-own book for any professional SQL developer.
Computing table content differences
with Oracle SQL
The question "what is the difference between two tables? is
simple to ask, but difficult to code. It's like an "anti-union" where we
seek only the unique rows within each table.
Tropashko has a great analysis of this common SQL problem from
both a mathematical perspective and a practical Oracle perspective. It also
shows an undocumented technique for improving execution speed for querying the
non-intersection of two tables.
Vadim notes that the _convert_set_to_join parameter can
be used when comparing the contents of two tables. This type of SQL query
is called a "semantic difference", or an "anti-union" operation. Tropashko
depicts the table comparison problem below:
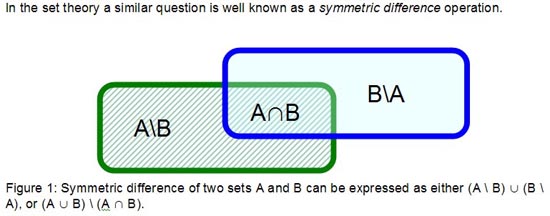
In the above figure we read the "/" as "not
in" and the "∪"
as "union". In sum, we want the table comparison SQL to find:
Rows in table A that are
not in table B
plus
Rows in table B that are
not in table A
Vadim notes that the obvious solution van
have poor performance:
The figure 1 with the expressions (A \
B) ∪ (B \
A) and (A ∪
B) \ (A ∩
B) pretty much exhaust all the theory involved. It is straightforward to
translate them into SQL queries. Here is the first one:
(select * from A
minus
select * from B) --
Rows in A that are not in B
union all
(
select * from B
minus
select * from A
) -- rows in B that are
not in A
In practice, however, this query is a
sluggish performer. With a na?e evaluation strategy, the execution flow and
the operators are derived verbatim from the SQL which we have written.
First, each table has to be scanned twice. Then, four sort operators are
applied in order to exclude duplicates. Next, the two set differences are
computed, and, finally, the two results are combined together with the union
operator. . .
After executing the symmetric difference
query, and capturing the row-source execution statistics (from the
v$sql_plan_statistics view) we get the following result:
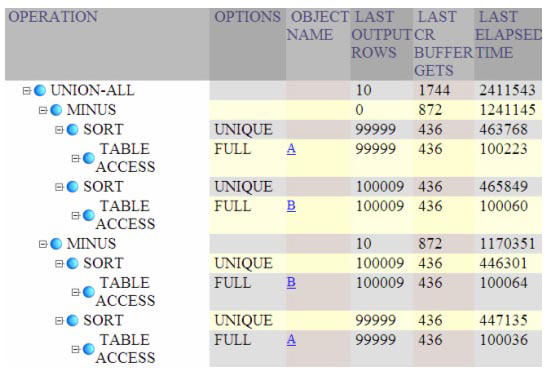
Execution plan for comparing the contents of two tables with MINUS operator
Rewriting Oracle SQL MINUS operator
with a NOT IN subquery
Vadim notes that the Oracle query
rewrite might come into play where a "set operation" (the minus operator) might
be converted into a join by the CBO:
It confirms our intuition on the
number of table scans and sorts. It also reveals that the time scanning a
single table (about 100 msec) is small compared to the time spent when
sorting each table (about 450 msec). Therefore we could try to aim lower
than 2.4 sec of total execution time.
This is not the only possible execution plan for the symmetric difference
query. Oracle has quite sophisticated query rewrite capabilities, and
transforming set operation into join is one of them.
In our example, both minus
operators could be rewritten as anti-joins. As of version 10.2, however,
this transformation is not enabled by default, and used as part of view
merging/ query unnesting framework only. It can be enabled with
alter session set "_convert_set_to_join"=
true;
The other alternative is to rewrite the SQL query manually [replacing the
minus operator with a NOT IN subquery] evidences about 30% improvement in
execution time . . .
select *
from A
where (col1,col2,?) not in
(select col1,col2,? from B)
union all
select * from B
where (col1,col2,?) not in
(select col1,col2,? from A);
The new execution statistics are very different and faster, using hash
joins:
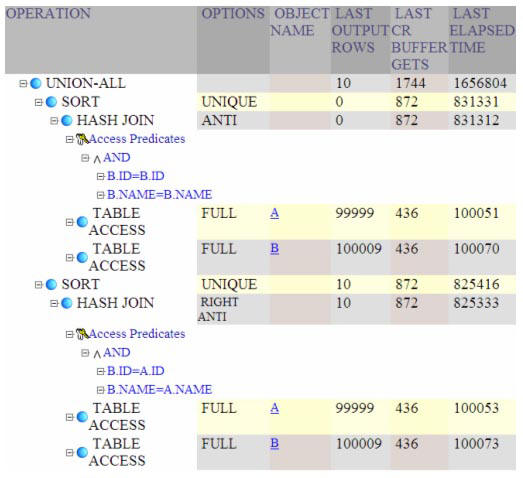
Execution plan for comparing the contents of two tables with NOT IN subquery
Disabling sort merge and hash joins
Tropashko notes
that the hash joins may not be the fastest table join method and he removes them
by unsetting the hash_join_enabled parameter and reviews the resulting
nested loops table join method:
alter session set
"_hash_join_enabled" = false;
alter session set "_optimizer_sortmerge_join_enabled" = false;
The particular query that we are
studying in this section has 5 query blocks: 2 pairs of selects from the
tables A and B, and one set operation. After this query is transformed, it
would consist of only 3 query blocks which we might witness from the
QBLOCK_NAME column of the PLAN_TABLE.
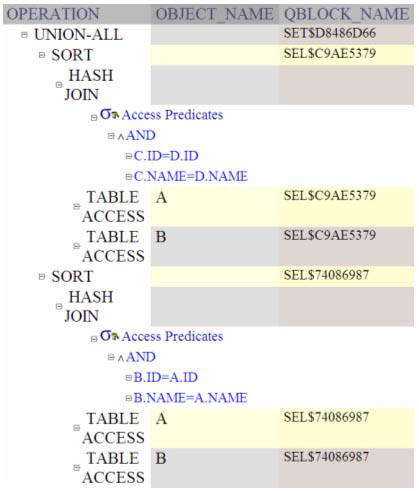
Execution plan for comparing the contents of two tables with sort
merge disabled
Forcing nested loop joins
Vadim next tries forcing nested loop joins with
the use_nl hint and discovers that the execution speed gets worse, not
faster:
Those query block names allow
directing the hints to the query blocks where they are supposed to be
applied. In our case, the joint method can be hinted as
/*+ use_nl(@"SEL$74086987" A)use_nl(@"SET$D8486D66"
B)*/
which produces the following rowsource level execution statistics:
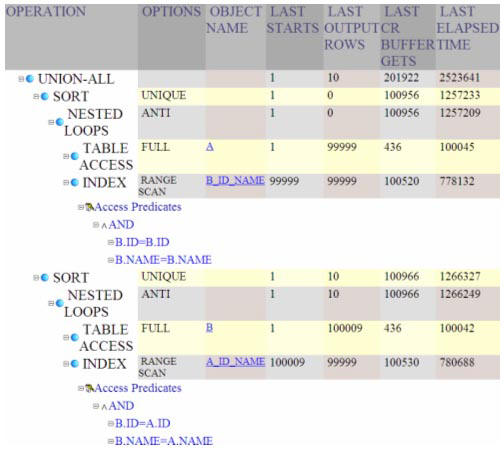
Execution plan for comparing the
contents of two tables with nested loop joins
From the statistics output we see
significant increase in buffer gets which is not offset by any noticeable
improvement in the execution time. It is fair to conclude that indexed
nested loops didn't meet our performance expectations in this case.
Using SQL aggregation to compute the
difference between two tables
Tropashko notes
that this anti-union semantic difference problem can also be solved using the
SQL CASE operator with in-line views (select statements in the FROM clause).
He notes a decrease in buffer gets, but no change in overall execution time:
select * from (
select id, name,
sum(case when src=1 then 1 else 0 end) cnt1,
sum(case when src=2 then 1 else 0 end) cnt2
from
(
select id, name, 1 src from A
union all
select id, name, 2 src from B
)
group by id, name
)
where cnt1 <> cnt2;
This is appeared as rather elegant solution where each table has to be
scanned once only, until we capture execution statistics. Although we
succeeded decreasing buffer gets count in half, the execution time still
remained around 2 sec.

Execution plan for comparing the
contents of two tables with SQL aggregation
Hash Value based Table Comparison SQL Syntax
Tropashko notes
yet another technique for using SQL to compare the contents of two tables
using a hash-based method:
When comparing data in two tables with identical signatures
there actually are two questions that one might want to ask:
-
Is there any difference? The expected answer is Boolean.
-
What are the rows that one table contain, and the other
doesn't.
Answering the second question implies that we can answer the first, yet, it
is possible that the first query might have better performance. We?ll
approach it with the hash-based technique in mind.
The standard disclaimer of any hash-based method is that it
is theoretically possible to get a wrong result. The rhetorical question,
however, is how often did the reader experience a problem due to hash value
collision? I never did. Would a user accept a tradeoff: significant
performance boost of the table difference query at the expense of remote
possibility of getting an incorrect result?
The idea of hash based method is associating a single hash
value with a table. This hash value behaves like aggregate, and therefore,
it can be calculated incrementally: if a row is added into a table, then a
new hash value is a function of the old hash value and the added row.
Incremental evaluation means good performance, and the two hash values
comparison is done momentarily.

Comparing
the contents of two tables with SQL hash weighting
Figure 2 is a method to ?weight? a table into a single value
involves concatenating all the fields per each row first. Then a
concatenated string is mapped into a number -- hash value. Finally all hash
values are aggregated into a single one. Had a single field in a single row
have change, the table weight would change as well.
A naive implementation is as simple as this SQL:
select sum(DBMS_UTILITY.get_hash_value(id||'|'||name,
1,
POWER(2,16)-1))
from A
union all
select sum(DBMS_UTILITY.get_hash_value(id||'|'||name,
1,
POWER(2,16)-1))
from B;
We concatenate all the row fields (with a distinct separator,
in order to guarantee uniqueness), then translate this string into a hash
value.
Using get_hash_values to computer table row differences
Tropashko notes
that you can use the dbms_utility packages get_hash_value
procedure to rewrite this query with the POWER clause:
Alternatively, we could have calculated hash values for each
field, and then apply some asymmetric function in order for the resulting
hash value to be sensitive to column permutations:
select sum(DBMS_UTILITY.get_hash_value(id
1,
POWER(2,16)-1)
+ 2*DBMS_UTILITY.get_hash_value(name
1,
POWER(2,16)-1))
from A
union all
select sum(DBMS_UTILITY.get_hash_value(id
1,
POWER(2,16)-1)
+ 2*DBMS_UTILITY.get_hash_value(name
1,
POWER(2,16)-1))
from B;
Row hash values are added together
with ordinary
sum
aggregate, but we could have written a modulo
216-1
user-defined aggregate
hash_sum
in the spirit of CRC (Cyclic Redundancy Check) technique.
For more on advanced Oracle SQL
tuning, see Vadim Tropashko's book "SQL
Design Patterns: The Expert Guide to SQL Programming"
 |
|
Get the Complete
Oracle SQL Tuning Information
The landmark book
"Advanced Oracle
SQL Tuning The Definitive Reference" is
filled with valuable information on Oracle SQL Tuning.
This book includes scripts and tools to hypercharge Oracle 11g
performance and you can
buy it
for 30% off directly from the publisher.
|


