| |
|
|
|
Keywords in Oracle
Expert Oracle Tips by Steve Callan
February 11 , 2015
|
Keywords in Oracle
By Steve Callan
Some words in Oracle have
special meaning. Maybe not to you, but then you're not the one
having to parse, execute and fetch what you type. To be more
precise, the 'some words' in the first sentence can be
categorized as reserved words and keywords. Within the keywords
category, context comes into play because a word isn't always
reserved. For example, the word COMMIT by itself triggers many
events, so you'd probably assume COMMIT is one of those words
that Oracle has a death grip on. From Oracle's perspective, no
one but me can use that word. As it turns out, COMMIT isn't held
that closely. You can create a table named COMMIT if you so
desire because COMMIT is a keyword, a lower classification than
that of a reserved word.

A reserved word is locked down,
whereas a keyword can be used under certain conditions. Auditing
is a valuable tool or feature, and if you wanted to create your
own audit table, could you issue a 'create table audit (...)'
statement?
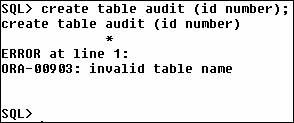
At least in SQL, no, you may not
use 'audit' that way. So, how can you tell (or where can you
find out) what the special words are, since those are clearly
the ones you don't want to step on? Several guides within the
documentation library (typically in an index) contain lists, but
the one definitive and one-stop source is the V$RESERVED_WORDS
data dictionary view.
At a high level, the name of the
view suggests that this is only about reserved words; but when
describing the view, the key column of interest is named
KEYWORD. That seems confusing given that I just went into detail
about the difference between a reserved word and a keyword. It
turns out that a second column in the view also matters:
RESERVED. The decoder ring for V$RESERVED_WORDS then is this:
|
RESERVED value |
Meaning |
|
Y |
Is a reserved word |
|
N |
Is not a reserved word |
The Database Reference guide
shows exactly that meaning within the description of
V$RESERVED_WORDS. The view has several other columns, and what
they reveal (or not) is interesting. Take LENGTH for example.
The column, as the name suggests, represents the length of the
keyword. This raises two questions. First, why does the length
matter? Second, why is the length stored as an attribute when it
can be easily derived? (Which normal form does that violate?)
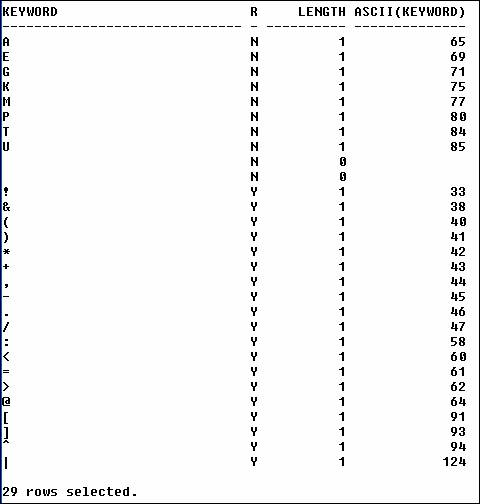
In Oracle 10g, there are 27
keywords with length of one, and 29 with length one or null.
What are the one or less length keywords (and their reserved
status)? I?m considering length one because that will generally
include symbols. The keyword of '>>' could be included as well,
but then the number of words to consider increases beyond what's
of interest here.
|
Keyword (reserved) |
Keyword (not reserved) |
|
|
:
-
[
<
]
!
*
>
(
=
.
@
^
/
,
)
+
& |
E
A
G
M
K
U
P
T
|
There are two instances of a
null or blank value in the non-reserved keyword column. Do they
represent a space, null or something else? Hard to tell since
neither has an ASCII value. If one represented some form of
whitespace, perhaps we?d see an 8, 9, 10, or 32 for a backspace,
tab, new line, or space, respectively.
Let's dig deeper into the view
definition and see where the values come from. Using Toad and
drilling down into the script for GV_$RESERVED_WORDS (under the
SYS schema, VIEWS), we see the following:
SELECT inst_id, keyword, LENGTH,
DECODE (MOD (TRUNC (TYPE / 2), 2), 0, 'N', 1, 'Y', '?') reserved,
DECODE (MOD (TRUNC (TYPE / 4), 2), 0, 'N', 1, 'Y', '?') res_type,
DECODE (MOD (TRUNC (TYPE / 8), 2), 0, 'N', 1, 'Y', '?') res_attr,
DECODE (MOD (TRUNC (TYPE / 16), 2), 0, 'N', 1, 'Y', '?') res_semi,
DECODE (MOD (TRUNC (TYPE / 32), 2), 0, 'N', 1, 'Y', '?') duplicate
FROM x$kwddef;
After formatting some columns
and ordering by type (only for length <= 1), the output is:
ADDR INDX INST_ID KEYWORD LENGTH TYPE
-------- ---------- ---------- ------- ------- ------
607DE010 1140 1 0 1
607DD48C 1073 1 E 1 1
607DC8B0 1004 1 A 1 1
607D6818 442 1 G 1 1
607D3B3C 181 1 M 1 1
607DC070 956 1 K 1 1
607DA230 780 1 U 1 1
607DE03C 1141 1 0 1
607D37A0 160 1 P 1 1
607DC40C 977 1 T 1 1
607D8E14 663 1 | 1 2
607D8FF8 674 1 : 1 2
607DA364 787 1 - 1 2
607DAA70 828 1 [ 1 2
607DADE0 848 1 < 1 2
607DBB74 927 1 ] 1 2
607DBE8C 945 1 ! 1 2
607DC82C 1001 1 * 1 2
607D8BAC 649 1 > 1 2
607D7D10 564 1 ( 1 2
607D7108 494 1 = 1 2
607D6CBC 469 1 . 1 2
607D6978 450 1 @ 1 2
607D4FDC 301 1 ^ 1 2
607D45B8 242 1 / 1 2
607D3A34 175 1 , 1 2
607D2B6C 89 1 ) 1 2
607D1F38 18 1 + 1 2
607D2300 40 1 & 1 2
The TYPE column is used as a
bucket for grouping words. Overall, the counts of types are:
SQL> select type, count(*)
2 from x$kwddef
3 group by type
4 order by 1;
TYPE COUNT(*)
---------- ----------
1 998
2 95
9 2
16 29
33 14
34 4
Using the value of type as an
indicator, designating a word as a duplicate means having a type
value high enough (above 32) so that the truncation of the
division is above one. The 18 duplicate-valued words are:
KEYWORD
---------------------
PRIVILEGE
NOPARALLEL_INDEX
NESTED_TABLE_SET_REFS
INTEGER
NOREWRITE
REFERENCING
NO_FILTERING
SB4
UB2
INDEX_RS
SMALLINT
NOCPU_COSTING
PARALLEL
ROLES
MAXARCHLOGS
CONSTRAINTS
DECIMAL
CHAR
Are these words really
duplicates of other keywords? By count, the answer is no. There
is only a difference of two between the count of distinct words
(1140) and total words (1142). Is it somehow related to the
purpose or function of the word, that is, is CHAR a (rough)
duplicate of VARCHAR2? If that were the case, then VARCHAR (or
VARCHAR2, pick one) should be a duplicate as well. The meaning
of duplicate, then, is somewhat of a mystery.
Let's look at the problem from
Oracle's (the company) perspective. A technical writer on an OTN
forum posting
acknowledged a key issue behind creating new keywords. Many, if
not all, documented optimizer hints are keywords of one form or
another. Suppose you create a procedure named GO_FAST but then
in the next release of the RDBMS, a new (and we waited such a
long time for this!) hint named GO_FAST is now at your disposal.
You can begin to imagine the howls of complaints from customers
when established object names have to be renamed in order to not
conflict with reserved words in a new release.
Nonetheless, the number of (at
least) documented words has increased from 660 in 8.1.7.4 to
1142 in 10.2.0.3. What turns out when minusing the two views is
that 10g has 487 keywords not found in 8i, and 8i has two (not
counting the blanks) not found in 10g. Many of the newer words
are related to optimizer hints.
As a developer, you have to be
clever enough to pick a scheme that is unlikely to be used by
users. Alternatively, a scheme could be established in the
beginning of your RDBMS product that not only prevents users in
general from conflicting with it, but also only allows a few
select users to even see it in the first place. The X$ tables
come to mind for this.
I try to decipher the hidden
meaning behind X$ table names. Several sources have defined many
of them; one fairly extensive source is Note 175982.1 on
MetaLink. Even with that list, the meaning of 'kwddef' is not
shown. We know that the leading 'k' is for kernel, and I'd guess
that 'wddef' could be something related word definition.
The key is that what is named in
SYS is very safe from conflict, but what is exposed (via views,
as one way) in SYS risks conflicting with your code or naming
scheme. You've no doubt run across something like this already.
At certain levels within Oracle, there can be one and only one
name for an object. Users A and B can each have a table named
EMP, but there can be at most one and only one public synonym
with the same name that refers to EMP. Consider a user named A:
SQL> create table a.emp as select * from scott.emp;
Table created.
SQL> create public synonym emp for scott.emp;
Synonym created.
SQL> create public synonym emp for a.emp;
create public synonym emp for a.emp
*
ERROR at line 1:
ORA-00955: name is already used by an existing object
In Closing
Establishing a naming
convention, particularly with respect to keywords, reminds me of
the observation made by the knight guarding the Holy Grail (in
'Indiana Jones and the Last Crusade') when Donovan (Jones'
nemesis) drank from the wrong goblet and dies a horrible death:
'He chose...poorly.' Once keywords are chosen and a product is
released to users, adding more keywords (or changing a
non-reserved work into a reserved one) becomes problematic.
Seemingly harmless choices or decisions early on may limit your
choices in the future. Although allowing certain words to be
redefined may seem like you?re building in a lot of flexibility,
you may just be adding to confusion down the road.
To further complicate matters,
some of Oracle's keywords are also ANSI reserved words.
Moreover, if dealing with different systems, a keyword in system
A is likely not going to be a keyword in system B. Later on in
the movie, after Indiana picked the correct goblet, the knight
says, 'You have chosen wisely.' That may be hard to do when
given numerous words to choose from. Pick what you need now, and
if possible, set aside some reserved words just in case. It's
always easier to let them go than to try and claim them in the
future.
 |
|
Get the Complete
Oracle SQL Tuning Information
The landmark book
"Advanced Oracle
SQL Tuning The Definitive Reference" is
filled with valuable information on Oracle SQL Tuning.
This book includes scripts and tools to hypercharge Oracle 11g
performance and you can
buy it
for 30% off directly from the publisher.
|
|

|
|
