 |
|
Oracle 11g Data Compression Tips for the Database
Administrator
Oracle 11g Tips by Burleson Consulting
|
These is an excerpt from
the book "Oracle
11g New Features". Tests show that 11g compression
result is slower transaction throughput but creates less writes because of
higher row density on the data block.
See this
benchmark of transparent data encryption.
Also see this quick note on how to
compress Oracle tablespaces.
While it is true that data storage prices (disks) have fallen
dramatically over the last decade (and continue to fall rapidly), Oracle data
compression has far more appealing benefits than simply saving on disk
storage cost. Because data itself can be highly
compressed, information can be fetched off of the disk devices with less
physical IO, which radically improves query performance under certain
conditions.
Please note that there is common misconception that 11g table compression
decompresses data while reading and holds it in the uncompressed form in the
cache. That is not quite correct since one of the salient features of the
database compression is that we do not have to uncompress the data before
reading it and the data stays in the compressed form even in the cache.
As a result, Oracle table compression not only helps customers save disk
space, it also helps to increase cache efficiency since more blocks can now
fit in the memory.
According to the
Oracle whitepaper on 11g data compression, the CPU overhead for the
compress/decompress operations will be minimal. More important,
Oracle11g data compression will be a Godsend for shops that are constrained
by Federal regulation to archive their audit trails (HIPAA, SOX).
But best of all, because Oracle 11g
compression makes storage up to 3x cheaper, solid-state flash drives far
less expensive allowing Oracle shops to forever eliminate the high costs of
platter-disk I/O and enjoy data access speeds up to 300x faster.
Let's take a closer look at how one would
implement Oracle
11g Data Compression in order to achieve the optimal results.
It is expected that Oracle data compression will
eventually become a default for Oracle
systems, much like Oracle implemented the move from dictionary managed tablespaces to
locally managed tablespaces. Eventually, this data compression may become
ubiquitous, a general part of the Oracle database management engine, but its
important for the Oracle database administrator to understand the
ramifications of the data compression and have the ability to turn-off
compression at-will.
For example, super small servers (read PC's),
may not possess enough horsepower to absorb the small (but measurable)
overhead of the compress/decompress routines. Remember, there is
always a tradeoff between these costs vs. the
saving on disk storage and allowing for information to be retrieved with the
minimum amount of physical disk I/O.
A history of database compression
Data compression algorithms (such as the Huffman algorithm), have been around
for nearly a century, but only today are they being put to use within mainstream
information systems processing. All of the industrial strength
database offer some for of data compression (Oracle, DB2, CA-IDMS), while
they are unknown within simple data engines such as Microsoft Access and SQL
Server. There are several places where data can be compressed, either
external to the database, or internally, within the DBMS software:
Physical database compression
-
Hardware
assisted compression - IMS, the first commercially available database
offers Hardware Assisted Data Compression (HDC) which interfaces with the
3380 DASD to compress IMS blocks at the hardware level, completely
transparent to the database engine.
-
Block/page level compression - Historical database compression uses
external mechanisms that are invisible to the database. As block are
written from the database, user exits invoke compression routines to store
the compressed block on disk. Examples include CLEMCOMP, Presspack and
InfoPak. In 1993, the popular DB2 offers built-in tablespace level
compression using a COMPRESS DDL keyword.
Logical
database compression
Internal
Database compression operates within the DBMS software, and write pre-compressed
block directly to DASD:
-
Table/segment-level compression - A database administrator has always
had the ability to remove excess empty space with table blocks by using
Oracle Data Pump or Oracle's online reorganization utility
(dbms_redefinition). By adjusting storage parameters, the DBA can
tightly pack rows onto data blocks. In 2003, Oracle9i release 2
introduced a
table-level compression utility using a table DDL COMPRESS keyword, and
here is
Oracle's TPC-H compression benchmark from 2006 and this blogger noted
problems with the Oracle 9i compression:
"Secondly, we implemented data
segment compression, and now we have to keep running mods against the
sys.obj$ table to prevent "block too fragmented to build bitmap index"
errors."
-
Row level
compression - In 2006, DB2 extended their page-level compression with
row-level compression. Oracle 11g offers a row-level compression
routine.
-
Transparent data
encryption (TDE) - See here for
Oracle transparent data encryption Tips
Let's take a closer look at the historical
evolution of database compression.
External database compression
Legacy mainframe databases such as IDMS and DB2
allowed the DBA to choose any data compression algorithm they desired.
One popular database compression program was offered by Clemson University
(still a leader in
data compression technologies), and their compression programs were very
popular in the
early 1980's with their CLEMCOMP and CLEMDCOM programs. In
IDMS, a user exit in the DMCL allowed for the data compression routine to be
invoked "before put" (writes), and "after get" (reads). Internally,
all database compression routines try to avoid changing their internal
software and rely on user exits to compress the data outbound and decompress
the incoming data before it enters the database buffers. In general, data
compression techniques follows this sequence:
Read compressed data (decompress):
1 - The
database
determines that a physical read is desired and issues an I/O request.
2 - Upon
receipt of the data block from disk, Oracle un-compresses the data.
This happens in RAM, very quickly.
3 - The
uncompressed data block is moved into the Oracle buffer.
Write an compressed Oracle block (compress):
1 - The
database
determines that a physical write is desired and issues an I/O request.
2 - The
database
reads the data block from the buffer and calls a compression routine to
quickly uncompresses the data. This happens in RAM, very quickly.
3 - The
compressed data block is written to disk.
Of course, database compression has evolved
dramatically since it was first introduced in the early 1980's, and Oracle
11g claims to have one of the best database compression utilities ever made.
Let's take a closer look.
Oracle Compression Overview
Over the
past decade Oracle introduced several types of compression so
we must be careful to distinguish between the disparate tools. The 11g data
compression is threshold-based and allows Oracle to honor the freelist
unlink threshold (PCTFREE) for the compress rows, thereby allowing more rows
per data block.
-
Simple index compression in Oracle 8i
-
Table-level
compression in Oracle9ir2 (create table mytab COMPRESS)
-
LOB
compression (utl_compress)
in Oracle 10g
-
Row-level
compression in Oracle 11g, even for materialized views (create table
mytab COMPRESS FOR ALL OPERATIONS; )
The historical external compression (blocks
are compressed outbound and uncompressed before presenting to the database)
are far simpler because all index objects are treated the same
way, whereas with the 11g table compression, a data block may contain both
compressed and uncompressed row data.
For the official details on Oracle 11g table data compression,
see
the
Oracle 11g concepts documentation. Oracle says
that their software will perform a native disk read on the data block, only
decompressing the row data after the physical I/O has been completed.
Within the
data buffers, the fully uncompressed version of the data remains, even though the information remains compressed on the
disk data
blocks themselves. This leads to a discrepancy between the size of
information on the data blocks and the size of the information within the
data buffers. Upon applying Oracle data compression, people will find
that far more rows will fit on a data block of a given size, but there is
still no impact on the data base management system from the point of view of the
SGA (system global area).
Because the decompression routine is called upon
block fetch, the Oracle data buffers remain largely unchanged while the data
blocks themselves tend to have a lot more data on them. This
Oracle 11g data compression whitepaper describes the data compression
algorithm:
Compressed blocks contain a structure called a symbol table that
maintains compression metadata.
When a block is compressed, duplicate values
are eliminated by first adding a single copy of the duplicate value to the
symbol table. Each duplicate value is then replaced by a short reference to
the appropriate entry in the symbol table.
Through this innovative design, compressed data is self-contained
within the database block as the metadata used to translate compressed data
into its original state is contained within the block.
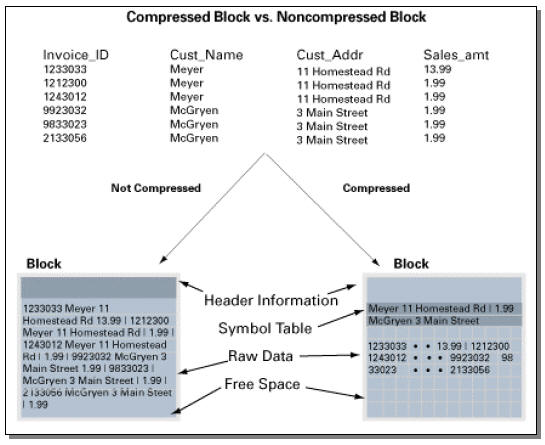
Oracle 11g compression (Source: Oracle Corporation)
In today's Oracle database management
systems, physical disk I/O remains one of the foremost bottlenecks.
Even at relatively fast speeds of 10 milliseconds, many data intensive Oracle
applications can still choke on I/O by having disk enqueues, Oracle block
read tasks
waiting to pull information from the spinning platters. Data compression is
certainly useful for reducing the amount of physical disk I/O but there are
some caveats that need to be followed by the Oracle database administrator.
Costs and Benefits of 11g compression
One of the exciting new features of Oracle 11g is the
new inline data
compression utility that promises these benefits:
-
Up
to a 3x disk savings - Depending on the nature of your data, Oracle
compression will result in huge savings on disk space.
-
Cheaper
solid-state disk - Because compressed tables reside on fewer disk
blocks, shops that might not otherwise be able to afford
solid-state flash disk
can now enjoy I/O speeds up to 300x faster than platter disk.
-
Faster
full scan/range scan operations - Because tables will reside on less
data blocks, full table scans and index range scans can retrieve the rows
with less disk I/O.
-
Reduced
network traffic - Because the data blocks are compressed/decompressed
only within Oracle, the external network packets will be significantly
smaller.
Tests show that 11g compression result is slower
transaction throughput but creates less writes because of higher row density on
the data block. See this
benchmark of
transparent data encryption.
Note: When rows are
first inserted into a data block, Oracle does not compress the row.
Oracle compression always begins after the first row insert when a
subsequent inserts takes block free space. At this time, all existing
rows within the block are compressed.
Overall, the benchmark slows that I/O writes being reduced
while CPU increases, resulting in slowing SQL throughput:
-
Slower transaction throughput – As we
expect, Oracle transactions run faster without the encryption/decryption
processing overhead. This encryption benchmark shows significantly
slower throughput when deploying TDE, almost 20% (81 transactions/second
with TDE, 121 transactions/second with TDE).
-
Less Disk Writes – Since transparent
data encryption compresses the data, the benchmark with TDE required less
disk writes.
-
More CPU required - As we would
expert, TDE required CPU cycles for the encrypt/decrypt operations, and in
this benchmark test we see User CPU rise from 46 to 80 when using TDE data
encryption.
The overhead of 11g compression?
Remember, physical disk I/O against disk
platters has become the major system bottleneck as the speed of processors
increase. Until the widespread adoption of RAM disk (solid state disk),
we can see this type of data compression being widely used in order to
reduce the amount of physical disk I/O against Oracle systems.
The internal machinations of Oracle have
always been a closely-guarded secret, Oracle's internal software, their
bread-and-butter "edge" that gives Oracle such a huge competitive advantage
over their competition. Because Oracle withholds many internal details, we
must we must discover the internals of 11g compression with with real-world
observations and conjecture.
First,
Oracle
hires some of the brightest software engineers in the world (graduates of
prestigious colleges like MIT), and it's likely that overhead will be
minimized by doing the data compress/uncompress only once, at disk I/O time,
and kept in decompressed form somewhere within the RAM data buffers.
It's clear that 11g data compression offers
these huge benefits, but the exact overhead costs remain unknown.
Oracle explains that there new 11g data compression algorithm:
"The algorithm works by
eliminating duplicate values within a database block, even across multiple
columns. Compressed blocks contain a structure called a symbol table that
maintains compression metadata.
When a block is compressed,
duplicate values are eliminated by first adding a single copy of the
duplicate value to the symbol table. Each duplicate value is then replaced
by a short reference to the appropriate entry in the symbol table."
Here is a 2005
benchmark test on Oracle table compression, with results indicating that
the 11g data compression is even faster than this 2005 version. Among
the findings is the important suggestion that using Oracle table compression
may actually improve the performance of your Oracle database:
“The reduction of disk
space using Oracle table compression can be significantly higher than standard
compression algorithms, because it is optimized for relational data.
It has virtually no
negative impact on the performance of queries against compressed data; in fact,
it may have a significant positive impact on queries accessing large amounts of
data, as well as on data management operations like backup and recovery.”
This compression paper also
suggestion that using a large blocksize may benefit Oracle databases where rows
contain common redundant values:
“Table compression can
significantly reduce disk and buffer cache requirements for database tables.
Since the compression algorithm utilizes data redundancy to compress data at a
block level, the higher the data redundancy is within one block, the larger the
benefits of compression are.”
The article also cites evidence
that Oracle table compression can reduce the time required to perform
large-table full-able scans by half:
“The fts of the
non-compressed table takes about 12s while the fts of the compressed table takes
only about 6s.”
Some unknown issues (as of September 2007) with
implementing Oracle11g data compression include the amount of overhead.
The compress/decompress operations are computationally intensive but super
small (probably measured in microseconds). This CPU overhead might be
significantly measurable, but we can assume that the overhead will be the
same (or smaller) than data compression in legacy databases (with the possible exception of
PC-based Oracle databases). In a perfect implementation, incoming data would only
be decompressed once (at read time) and the uncompressed copy of the disk
block would reside in RAM, thereby minimizing changes to the Oracle kernel
code. The overhead on DML must involve these operations:
- Overhead at DML
time - Whenever a SQL update, insert of delete changes a data
block in RAM, Oracle must determine if the data block should be unlinked
from the freelist (this threshold is defined by the PCTFREE parameter).
- Compression on write - An outbound data block must be
compressed to fit into it's tertiary block size (as defined by db_block_size and the tablespace
blocksize keyword).
For example, an uncompressed block in RAM might occupy up to 96k in RAM
and be compressed into it's tertiary disk blocksize of 32k upon a
physical disk write.
- Decompress on read
- At physical read time, incoming disk blocks must be expanded once and
stored in the RAM data buffer. The exact mechanism for this
expansion is not published in the Oracle11g documentation, but it's most
likely a block versioning scheme similar to the one used for maintaining
read consistency.
- Increased
likelihood of disk contention - Because the data is tightly
compressed on the data blocks, more rows can be stored, thus increasing the
possibility of "hot" blocks on disk. Of course, using large data
buffers and/or solid-state disk (RAM-SAN) will alleviate this issue.
Without implementing this revolutionary
"partial" row compression, making a table-wide or tablespace-wide
compression change would require a massive update to blocks within the
target tablespace. The 11g compression docs note that when changing to/from
global compression features, the risk averse DBA would choose to rebuild the
table or tablespace from scratch:
"Existing data in the database can also
be compressed by moving it into compressed form through
ALTER
TABLE and
MOVE
statements. This operation takes an exclusive lock on the
table, and therefore prevents any updates and loads until it
completes. If this is not acceptable, the Oracle
Database online redefinition utility (the
DBMS_REDEFINITION PL/SQL package) can be used."
Operational tests of the 11g data compression
utility
Roby Sherman
published some negative test results about the 11g data compression
utility, suggesting that there may be some performance issues, noting that
his performance was "quite horrible". However, this does not
match the experience of others, and it serves to underscore the issue that
data compression is marginally CPU intensive, and 11g table compression may
not be performant on smaller personal computers:
For anyone interested, I ran some very quick benchmarks on
11g's new Advanced Compression table option COMPRESS FOR ALL OPERATIONS that
Oracle is claiming was "specifically written to create only the most
'minimal' of performance impacts in OLTP environments.
I guess their definition of minimal and my definition of minimal must be
different..
Other comments of Sherman's 11g compression
test included:
Rather than commenting
that the advanced compression is "quite horrible" I'd comment that your
choice of tests are quite horrible.
I don't consider Roby's
test cases are horrible. Anyone who criticizes the hype seems to be
criticized. Look at the argument of Roby: "But, then again, if your
operations are that minimal, you probably aren't creating enough data to
need compression in the first place!"
Robert
Freeman noted that his results did not
show the same degradation and he offers insightful comments about the
dangers of using a "negative proof":
"I've read this particular post several times. I just have to believe
that I'm not getting something here, because ..... I want to be charitable
but the point that is being made is just asinine in my opinion. I hope, I
really hope, that I've missed something obvious and that I'm the fool (would
not be the first time - I freely confess my imperfections).
>> The
common nonsense peddled is like: It all depends.
EXCUSE ME?????
Common nonsense? The whole scientific method is all about Ceteris paribus.
Research is influenced heavily on IT DEPENDS. Drop a rock and a feather on
the Earth and then on the moon and tell me the results are not a matter of
IT DEPENDS. I must have missed your point, because nobody could be so short
sighted as to presuppose that there are no dependencies.
Can you
explain negative cases? Sure. I can explain the negative case of the rock
falling faster than the feather to the difference in location and criteria
of the experiment. I can explain Roby's negative results in numerous ways,
including accepting the *possibility* that his results reflect truth, and
that compression is a performance killer. Did he provide sufficient evidence
to review his results, of course not. How do we know the issue isn't one of
the optimizer changing the plan, as opposed to the physical implementation
of compression, for example? We don't because no execution plans were
provided.
That being said, his results do not mirror mine. Explain
that negative case. Oh, is it because my results are on Oracle Beta 5?
Or is it that my results are on a faster CPU? Can we always explain
negative cases? No. . .
Additionally, I argue that one can never,
ever, systematically prove everything 100%. Perhaps to a high degree of
confidence, but never for sure. Why? Because the conditions of that result
and that analysis can change because the dependencies change. You can not
control the entire environment, thus you can not 100% guarantee an outcome,
ever. If you have never had the frustrating experience of having two
different result sets and not being
able to figure out why they differ,
then you are luckier than I (or younger, or you have more time or less
experience).
. . .
While I have not tested compression in the
production code (yet, I'm running the book through production now), when I
did my chapter on compression in Beta 5, I found the results to be very
different from Roby's. Still, I'm glad to see him testing this stuff and
reminding us that not every new feature is a panacea."
But these
unverifiable reports from DBA are not conclusive and we need a reproducible
benchmark to ascertain the true costs and benefits of using Oracle 11g
compression.
A
benchmark of 11g compression with SSD
To see the
effects of Oracle 11g data compression we need a reproducible benchmark test
that illustrates the benefits and costs of utilizing 11g compression,
especially with SSD flash drives.
A
reproducible TPC-H benchmark can conclusively show these performance
benefits for using Oracle 11g data compression with SSD:
-
Solid-state Oracle becomes cheaper - This test is expected to show
that the use of Oracle 11g compression can half the costs of solid-state
RAM-SAM, making diskless Oracle far more cost effective.
-
Scan
operations up to 200 times faster - The benchmark is expected to
confirmed a dramatic speed improvement for index range scans and full
scan operations, including full-table scans and index fast full scans.
The performance benefit for combining 11g compression and SSD is
expected to improve performance by several orders of magnitude.


