One of the most exciting, yet most overlooked,
features of Oracle databases is the ability to dedicate multiple processors to
service an Oracle query. The Oracle database has implemented parallel query
features that allow a query to effectively use both symmetric multiprocessors
(SMP) and massively parallel processors (MPP). Using these features, it is
possible to read a one-gigabyte table with sub-second response time. Let's begin
with a review of these architectures. We'll follow up tomorrow with a look at
tips for using parallel queries.
A little background
Beginning in the 1960s, IBM began to implement mainframe
processors with multiple CPUs. These were known as dyadic (two processors) or
quadratic (four processors). Once these processors were implemented, software
and database developers struggled with developing products that could take
advantage of the ability to use multiple processors to service a task. These
tools generally took the form of segmentation features that dedicated specific
tasks to specific processors. They did not incorporate any ability to
dynamically dedicate tasks to processors or to load-balance between CPUs.
Once the UNIX operating system became popular in the 1980s, hardware vendors
(SUN, IBM, and Hewlett-Packard) began to offer computers with multiple CPUs and
shared memory. These were known as SMP processors. On the other end of the
spectrum, hardware vendors were experimenting with machines that contained
hundreds, and even thousands, of individual CPUs. These became known as
massively parallel processors.
As the Oracle database grew in popularity, the Oracle architects began to
experiment with techniques that would allow the Oracle software to take
advantage of these parallel features. However, it is not necessary to have
parallel processors (SMP or MPP) in order to use and benefit from parallel
processing. Even on the same processor, multiple processes can speed up queries.
Using Oracle parallel query
Oracle version 7.2 and above can partition an SQL query into
sub-queries and dedicate separate processors to each one. At this time, parallel
query is useful only for queries that perform full-table scans on long tables,
but the performance improvements can be dramatic.
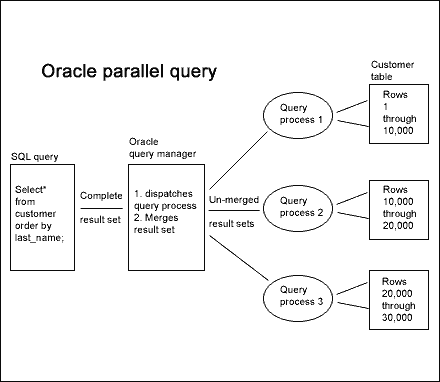
Here's how it works. Instead of having a single query server to manage the I/O
against the table, parallel query allows the Oracle query server to dedicate
many processes to simultaneously access the data. (See Figure A).
|
|
|
Figure A
|
|
|
|
|
To be most effective, the table should be partitioned onto separate disk
devices, such that each process can do I/O against its segment of the
table without interfering with the other simultaneous query processes.
However, the client-server environment of the 1990s relies on RAID or a
logical volume manager (LVM), which scrambles data files across disk packs
in order to balance the I/O load. Consequently, full utilization of
parallel query involves "striping" a table across numerous data
files, each on a separate device.
Even if your system uses RAID or LVM, there are still some performance
gains from using parallel query. In addition to using multiple processes
to retrieve the table, the query manager will also dedicate numerous
processes to simultaneously sort the result set. (See Figure B.)
|
|
|
Figure B
|
|

|
|
|
However, parallel query works best with symmetric multiprocessor
(SMP) boxes. Also, it is important to configure the system to
maximize the I/O bandwidth, either through disk striping or
high-speed channels. Because of the parallel sorting feature, it is
also a good idea to beef up the memory on the processor.
While sorting is no substitute for using a pre-sorted index, the
parallel query manager will service requests far faster than if you
use a single process. The data retrieval itself will not be
particularly fast, since all of the retrieval processes are
competing for a channel on the same disk. But each sort process has
its own sort area (as determined by the sort_area_size init.ora
parameter), so the sorting of the result set will progress very
quickly.
In addition to full-table scans and sorting, the parallel query
option also allows for parallel processes for merge joins and nested
loops.
Query setup
Invoking the parallel query option requires several
steps. The most important is that the execution plan for the query
specifies a full-table scan. If the output of the execution plan
does not indicate a full-table scan, the query can be forced to
ignore the index by using query hints.
The number of processors dedicated to service an SQL request is
ultimately determined by Oracle query manager, but the programmer
can specify the upper limit on the number of simultaneous processes.
When using the cost-based optimizer, the PARALLEL hint can be
embedded into the SQL to specify the number of processes. For
instance:
select /*+ FULL(employee_table)
PARALLEL(employee_table, 4) */
employee_name
from
employee_table
where
emp_type = 'SALARIED';
If you are using SMP with many CPUs, you can issue a parallel
request and leave it up to each Oracle instance to use its default
degree of parallelism. For example:
select /*+ FULL(employee_table)
PARALLEL(employee_table, DEFAULT, DEFAULT) */
employee_name
from
employee_table
where
emp_type = 'SALARIED';
Parallel query parameters
Several important init.ora parameters have a direct
impact on parallel query:
-
sort_area_size—The higher the value,
the more memory available for individual sorts on each parallel
process. Note that the sort_area_size parameter allocates memory
for every query on the system that invokes a sort. For example,
if a single query needs more memory, and you increase the
sort_area_size, all Oracle tasks will allocate the new
amount of sort area, regardless of whether they will use all of
the space.
-
parallel_min_servers—This value
specifies the minimum number of query servers that will be
active on the instance. There are system resources involved in
starting a query server, and having the query server started and
waiting for requests will accelerate processing. Note that if
the actual number of required servers is less than the values of
parallel_min_servers, the idle query servers will be consuming
unnecessary overhead, and the value should be decreased.
-
parallel_max_servers—This value
specifies the maximum number of query servers allowed on the
instance. This parameter will prevent Oracle from starting so
many query servers that the instance cannot service all of them
properly.
Parallel dictionary queries
To see how many parallel query servers are busy at
any given time, the following query can be issued against the
v$pq_sysstat table:
select * from
v$pq_sysstat
where statistic = 'Servers Busy';
STATISTICVALUE
-------------------------------
Servers Busy30
In this case, we see that 30 parallel servers are busy at this
moment. Do not be misled by this number. Parallel query servers are
constantly accepting work or returning to idle status, so it is a
good idea to issue the query many times over a one-hour period. Only
then will you receive a realistic measure of how many parallel query
servers are being used.
Tomorrow, we'll continue our discussion of parallel features with a
look at how you can use parallel queries with your Oracle databases.
|
|
|
|
|
Oracle Training from Don Burleson
The best on site
"Oracle
training classes" are just a phone call away! You can get personalized Oracle training by Donald Burleson, right at your shop!

|
|
|
|
| |
|
Burleson is the American Team

Note:
This Oracle
documentation was created as a support and Oracle training reference for use by our
DBA performance tuning consulting professionals.
Feel free to ask questions on our
Oracle forum.
Verify
experience!
Anyone
considering using the services of an Oracle support expert should
independently investigate their credentials and experience, and not rely on
advertisements and self-proclaimed expertise. All legitimate Oracle experts
publish
their Oracle
qualifications.
Errata?
Oracle technology is changing and we
strive to update our BC Oracle support information. If you find an error
or have a suggestion for improving our content, we would appreciate your
feedback. Just
e-mail:
 and include the URL for the page. and include the URL for the page.

Copyright © 1996 - 2020
All rights reserved by
Burleson
Oracle ®
is the registered trademark of Oracle Corporation.
|
|
