Also see my notes on
"Introduction to Histograms", "
using the dbms_stats skewonly option", "all
about histograms" and "Oracle
Cardinality and histograms" for more details on using Oracle histograms to
improve execution plans.
IMPORTANT NOTE: Oracle dynamic sampling has been re-named
to Oracle adaptive statistics
in Oracle 12c.
Introduction to dynamic Sampling
One of the greatest problems with the Oracle
Cost-based Optimizer (CBO) was not a problem
with the CBO at all, but with the failure of the
Oracle DBA to gather accurate schema statistics.
Even with the
dbms_stats package, the schema statistics
were often stale, and the DBA did not always
create histograms for skewed data columns and
data columns that are used to estimate the size
of SQL intermediate result sets.
This resulted in a ?bum rap? for Oracle?s CBO,
and beginner DBAs often falsely accused it of
failing to generate optimal execution plans when
the real cause of the sub-optimal execution plan
was the DBA?s failure to collect complete schema
statistics.
Note:
In release 11gr2 and beyond, the optimizer will
automatically determine if dynamic sampling
should be invoked and automatically determine
the best sampling level.
Hence, Oracle has automated the function of
collecting and refreshing schema statistics in
Oracle10g. This automates a very
important DBA task and ensures that Oracle will
always gather good statistics and choose the
best execution plan for any query. Using the
enhanced
dbms_stats package, Oracle will
automatically estimate the sample size, detect
skewed columns that would benefit from
histograms, and refresh the schema statistics
when they become stale.
begin
dbms_stats.gather_schema_stats(
ownname => 'SCOTT',
estimate_percent => dbms_stats.auto_sample_size,
method_opt => 'for all columns size skewonly',
degree => 7
);
end;
/
Sub-optimal SQL table join order
One
problem with the Oracle optimizer is that he
cannot always guess the inter-join result set
size, and histograms and dynamic sampling can
help. See this important note on
tuning with
Oracle histograms.
However, there was always a nagging problem with
the CBO. Even with good statistics, the CBO
would sometimes determine a sub-optimal
table-join order, causing unnecessarily large
intermediate result sets. For example, consider
the complex
WHERE
clause in the query below. Even with the best
schema statistics, it can be impossible to
predict a priori the optimal table-join
order (the one that has the smallest
intermediate baggage). Reducing the size of the
intermediate row-sets can greatly improve the
speed of the query.
select
stuff
from
customer
natural join
orders
natural join
item
natural join
product
where
credit_rating * extended_credit > .07
and
(qty_in_stock * velocity) /.075 < 30
or
(sku_price / 47) * (qty_in_stock / velocity) > 47;
In this example, the four-way table join only
returns 18 rows, but the query carries 9,000
rows in intermediate result sets, slowing-down
the SQL execution speed (refer to figure 1).
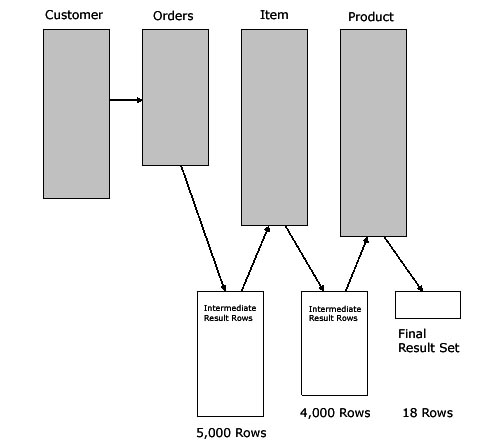
Figure 1: Sub-optimal intermediate row sets.
If we were somehow able to predict the sizes of
the intermediate results, we can re-sequence the
table-join order to carry less ?intermediate
baggage? during the four-way table join, in this
example carrying only 3,000 intermediate rows
between the table joins (refer to figure 2) .
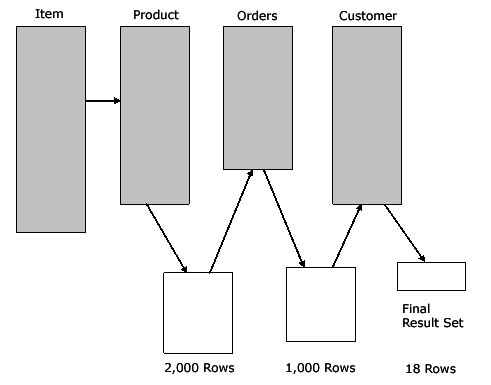
Figure 2: Optimal intermediate row sets.
Let?s take a closer look at this issue. Assume
that we have a three-way table join against
tables that all contain over 10,000 rows each.
This database has 50,000 student rows, 10,000
course rows and 5,000 professor rows (refer to
figure 3).

Figure 3: Number of rows in each table.
If the number of rows in the table determined
the best table-join order, we would expect that
any three-way table join would start by joining
the professor and course tables, and then would
join the
RESULT set to the student table.
Ah, but whenever there is a
WHERE
clause, the total number of rows in each table
does not matter (if you are using index access).
Here is the query:
select
student_name
from
professor
natural join
course
natural join
student
where
professor = ?jones?
and
course = ?anthropology 610?;
Stan Nowakowski
Bob Crane
James Bakke
Patty O?Furniture
4 Rows selected.
Despite the huge numbers of rows in each table,
the final result set will only be four rows. If
the CBO can guess a priori the size of
the final result, he can use sampling techniques
to examine the
WHERE
clause of the query and determine which two
table we should join together first.
There are only two table-join choices in our
simplified example:
1. Join (student to course) and (RESULT to
professor)
2. Join professor to course and (RESULT to
student)
So, then, which is better? The best solution
will be the one in which
RESULT
is smallest. Because the query is filtered with
a
WHERE
clause, the number of rows in each table is
incidental, and what we are really concerned
about is the number of rows ?where
professor = ?jones?? and ?where
course = ?Anthropology 610?.?
If we know, the best table-join order becomes
obvious. Assume that Professor Jones is very
popular and teaches 50 courses and that
Anthropology 610 as a total of eight students.
Knowing this, we can see that the size of the
intermediate row baggage is very different:
Join professor to course and (RESULT
to student).

Figure 4: A sub-optimal intermediate row
size.
If the CBO were to join the student table to the
course table first, the intermediate result set
would only be eight rows, far less baggage to
carry over to the final join:
Join (student to course) and (RESULT to
professor).

Figure 5: An optimal intermediate row size.
Now that we have only eight rows returned from
the first query, it easy to join the tiny
eight-row result set into the professor table to
get the final answer.
Cost-based Optimizer estimates of Join Cardinality
As we can see, in the absence of column
histograms, Oracle CBO must be able to ?guess?
this information, and it sometimes gets it
wrong. This is one reason why the
ORDERED
hint is one of the most popular SQL tuning
hints; using the
ORDERED
hint allows you to specify that the tables be
joined together in the same order that they
appear in the
FROM
clause, like this:
select /+ ORDERED */
student_name
from
student
natural join
course
natural join
professor
where
professor = ?jones?
and
course = ?anthropology 610?;
Remember, if the values for the professor and
course table columns are not skewed, then it is
unlikely that the 10g automatic
statistics would have created histograms buckets
in the
dba_histograms view for these columns.
As we can see, the Oracle CBO needs to be able
to accurately estimate the final number of rows
returned by each step of the query and then use
schema metadata (from running
dbms_stats) to choose the table-join
order that results in the least amount of
?baggage? (intermediate rows) from each of the
table join operations.
But this is a daunting task. When a SQL query
has a complex
WHERE
clause, it can if very difficult to estimate the
size of the intermediate result sets, especially
when the
WHERE clause transforms column values
with mathematical functions. This is because
Oracle has made a commitment to making the CBO
infallible, even when incomplete information
exists. However, Oracle9i introduced the new
dynamic sampling method
for gathering run-time schema statistics, and it
is now enabled by default in Oracle10g.
Note that dynamic sampling is not for every
database. Let?s take a closer look.
Dynamic Sampling and cardinality
estimates
The main objective of dynamic sampling is to
create more accurate selectivity and cardinality
estimates, which, in turn, helps the CBO
generate faster execution plans. Dynamic
sampling is normally used to estimate
single-table predicate selectivity when
collected statistics cannot be used or are
likely to lead to significant errors in
estimation. It is also used to estimate table
cardinality for tables without statistics or for
tables whose statistics are too out of date to
trust.
The optimizer_dynamic_sampling initialization
parameter controls the number of blocks read by
the dynamic sampling query. The parameter can be
set to a value from 0 to 10. In 9ir2,
optimizer_dynamic_sampling defaulted to a
value of "1", while in 10g and beyond, the
default for this parameter is set to ?2,?
automatically enabling dynamic sampling.
Beware
that the
optimizer_features_enable parameter will
turns off dynamic sampling if it is set to a
version earlier than 9.2.0.
A value of 0 means dynamic sampling will not be
performed. Increasing the value of the parameter
results in more aggressive dynamic sampling, in
terms of both the type of tables sampled
(analyzed or un-analyzed) and the amount of I/O
spent on sampling.
Oracle Dynamic Sampling restrictions
When
dynamic_sampling was first introduced in
Oracle9i, it was used primarily for data
warehouse systems with complex queries. Because
it is enabled by default in Oracle10g,
you may want to turn off
dynamic sampling to remove unnecessary
overhead if any of the following are true:
-
You have an online transaction processing
(OLTP) database with small, single-table
queries.
-
Your queries are not frequently re-executed
(as determined by the executions
column in v$sql and
executions_delta
in
dba_hist_sqlstat).
-
Your multi-table joins have simple
WHERE clause predicates with
single-column values and no built-in or
mathematical functions.
-
Dynamic sampling is ideal whenever a query
is going to execute multiple times because
the sample time is small compared to the
overall query execution time.
By sampling data from the table at runtime,
Oracle10g can quickly evaluate complex
WHERE
clause predicates and determine the selectivity
of each predicate, using this information to
determine the optimal table-join order. Let?s
use the Oracle SQL sample clause to see how this
works.
Sampling Table Scans for CBO estimates
A sample table scan retrieves a random sample of
data of whatever size you choose. The sample can
be from a simple table or a complex
SELECT
statement such as a statement involving multiple
joins and complex views.
To peek inside dynamic sampling, we can run some
simple SQL queries. The following SQL statement
uses a sample block and sample rows scan on the
customer table. (Note that there are
50,000 rows in this table.) The first statement
shows a sample block scan and the last one shows
a sample row scan:
select
count(*)
from
customer
sample block(20);
COUNT(*)
----------
12268
select
pol_no,
sales_id,
sum_assured,
premium
from
customer
sample (0.02) ;
POL_NO SALES_ID SUM_ASSURED PREMIUM
---------- ---------- ----------- ---------- --
2895 10 2525 2
3176 10 2525 2
9228 10 2525 2
11294 11 2535 4
19846 11 2535 4
25547 12 2545 6
29583 12 2545 6
40042 13 2555 8
47331 14 2565 10
45283 14 2565 10
10 rows selected.
We can use the new
dynamic_sampling hint to sample rows from
the table.
select /*+ dynamic_sampling(customer 10) */
pol_no,
sales_id,
sum_assured,
premium
from
customer;
POL_NO SALES_ID SUM_ASSURED PREMIUM
---------- ---------- ----------- ---------- --
2895 10 2525 2
3176 10 2525 2
9228 10 2525 2
11294 11 2535 4
19846 11 2535 4
25547 12 2545 6
29583 12 2545 6
40042 13 2555 8
47331 14 2565 10
45283 14 2565 10
Conclusions on dynamic sampling
Dynamic sampling addresses an innate problem in
SQL and this issue is common to all relational
databases. Estimating the optimal join order
involves guessing the sequence that results in
the smallest amount of intermediate row-sets,
and it is impossible to collect every possible
combination of WHERE clauses with a priori
statistics.
Dynamic sampling is a godsend for databases that
have large n-way table joins that execute
frequently. By sampling a tiny sub-set of the
data, the Oracle 10g CBO gleans clues as
to the fastest table-join order.
As we have noted,
dynamic_sampling does not take a long
time to execute, but it can be an unnecessary
overhead for all Oracle10g databases.
Dynamic sampling is just another example of
Oracle?s commitment to making Oracle10g
an intelligent, self-optimizing database.


