|
Inside V$Session_Wait
The
v$session_wait view displays information about wait
events for which active sessions are currently waiting. The
following is the description of this view, and it contains some
very useful columns, especially the P1 and P2 references to the
objects associated with the wait events.
SQL> desc v$session_wait
Name Null? Type
--------------------------- -------- ------------
SID NUMBER
SEQ# NUMBER
EVENT VARCHAR2(64)
P1TEXT VARCHAR2(64)
P1 NUMBER
P1RAW RAW(4)
P2TEXT VARCHAR2(64)
P2 NUMBER
P2RAW RAW(4)
P3TEXT VARCHAR2(64)
P3 NUMBER
P3RAW RAW(4)
WAIT_CLASS_ID NUMBER
WAIT_CLASS# NUMBER
WAIT_CLASS VARCHAR2(64)
WAIT_TIME NUMBER
SECONDS_IN_WAIT NUMBER
STATE VARCHAR2(19)
Using
v$session_wait, it is easy to interpret each wait
event parameter using the corresponding descriptive text columns
for that parameter. Also, wait class columns were added so that
various wait events could be grouped into the related areas of
processing such as network, application, idle, concurrency, etc.
This view provides the DBA with a dynamic snapshot of the wait
event picture for specific sessions. Each wait event contains
other parameters that provide additional information about the
event. For example, if a particular session waits for a
buffer busy
waits event, the database object causing this wait
event can easily be determined:
select
username,
event,
p1,
p2
from
v$session_wait
where
sid = 74;
The output of this query for a particular session with SID 74
might look like this:
USERNAME EVENT SID P1 P2
---------- ----------------- --- -- ---
PCS buffer busy waits 74 4 155
Columns P1 and P2 allow the DBA to determine file and block
numbers that caused this wait event. The query below retrieves the
object name that owns data block 155, the value of P2 above:
select
segment_name,
segment_type
from
dba_extents
where
file_id = 4
and
155 between
(block_id and block_id + blocks – 1);
SEGMENT_NAME SEGMENT_TYPE
------------------------------ ---------------
orders TABLE
The above output shows that the table named
orders caused this
wait event, a very useful clue when tuning the SQL within this
session. Also, see my notes on v$session_wait.
The ability to analyze and correct Oracle Database physical
read wait events is critical in any tuning project. The majority
of activity in a database involves reading data, so this type of
tuning can have a huge, positive impact on performance.
System wait tuning has become very popular because it can
show you those wait events that are the primary bottleneck for
your system. Some experts like the 10046 wait event (level 8 and
higher) analysis technique and Oracle MOSC now has an analysis
tool called trcanlzr.sql to interpret bottlenecks via 10046 trace
dumps. However, some Oracle professionals find dumps cumbersome
and prefer to sample real-time wait events.
When doing wait analysis, it is critical to remember that all
Oracle databases experience wait events, and that the presence of
waits does not always indicate a problem. In fact, all well-tuned
databases have some bottleneck. (For example, a computationally
intensive database may be CPU-bound and a data warehouse may be
bound by disk-read waits.) In theory, any Oracle database will run
faster if access to hardware resources associated with waits is
increased.

The Ion tool is
the easiest way to analyze STATSPACK wait event data in Oracle and Ion
allows you to spot hidden wait trends.
This article explores a small subset of wait analysis,
but it illustrates a critical concept of Oracle tuning: the fact that all Oracle
databases wait on some kind of system resource, and it's the Oracle
professional's job to determine whether the database is I/O bound, CPU bound,
memory bound, or bound waiting on latches or locks. When the source of the
bottleneck has been identified, the savvy Oracle professional must then
determine the causes of these events and attempt to remove them.
To aid us in identifying wait events, the Oracle
Database provides numerous views such as
v$system_event and v$session_wait to give us
insight into our wait events. While the
v$system_event dictionary views will give you
information regarding the total number of I/O-related waits within your Oracle
database, it does not tell you the specific object involved. In Oracle9i
Release 2 the v$segment_statistics
view gives this information.
The
v$session_wait view provides detailed file and
block data and you can extract the object from the block number. Remember,
Oracle event waits occur very quickly, and it is difficult to get data unless
you are lucky enough to run the query at the exact moment the database is
experiencing the wait. Hence, we must devise a method for using the
v$session_wait view
so we can capture a sample of the transient physical I/O waits.
If you look into the
v$system_event view
you will note that there are over 300 specific wait events. For the purpose of
this article, we will limit our discussion to the two main physical I/O wait
events. As you may recall, there are two critical I/O read waits within any
Oracle database:
- db file sequential read waits: A
sequential read wait occurs within an Oracle database when a single block is
read. A single read is most commonly an index probe by ROWID into an
individual table, or the access of an index block. Sequential reads are
single-block reads, as opposed to multiblock (scattered) reads.
- db file scattered read waits:
Scattered read waits occurs when multiblock I/O is invoked. When the Oracle
Database performs a full-table scan or sort operation, multiblock block read
is automatically invoked.
To tune these wait events, we must first identify
those objects that experience physical read waits and when they do so, and then
address the issue with tuning techniques. Let's start by reviewing the
solutions, and then look at how to identify wait conditions.
Solutions to Physical Read Waits
When we have identified the objects that experience
the physical read waits, we can use Statspack to extract the SQL associated with
the waits and take the following actions to correct the problem. These
corrective actions are presented in the order in which they are most likely to
be effective, and some may not apply to your environment.
- Tune the SQL: This is the single most
important factor in reducing disk waits. If an SQL statement can be tuned to
reduce disk I/O (for example, by using an index to remove an unnecessary
large-table full-table scan), then the amount of disk I/O and associated waits
are dramatically reduced. Other SQL tuning might include:
- Change table join order: For
sequential read waits, the SQL may be tuned to change the order that the
tables are joined (often using the ORDERED hint)
- Change indexes: You can tune the SQL
by adding function-based indexes or using an INDEX hint to make the SQL less
I/O-intensive by using a more selective index.
- Change table join methods: Often,
nested loop joins have fewer I/O waits than hash joins, especially for
sequential reads. You can change table join methods with SQL hints (USE_NL,
for example). If you are not yet using Oracle9i with
pga_aggregate_target,
you can change the propensity for hash join by adjusting the hash_area_size
parameter.
- Re-schedule contentious SQL: After you
have identified the regular trends of repeating disk waits, you can often
reschedule the execution of the SQL at another time, thereby relieving the
physical waits.
- Re-analyze schema using
dbms_stats
- In some cases, stale or non-representative statistics generated by the
dbms_utility.analyze_schema
package can cause suboptimal SQL execution plans, resulting in unnecessary
disk waits. The solution is to use the dbms_stats package to analyze your
schema. Also, note that if column data values are skewed adding histograms may
also be necessary.
- Distribute disk I/O across more spindles:
Sometimes disk channel contention is responsible for physical read waits,
which will show up in your disk monitor tool (iostat, EMC Symmetrics Manager,
and so on). If you experience disk waits as a result of hardware contention,
you can stripe the offending objects across multiple disk spindles by
reorganizing the object and using the MINEXTENTS and NEXT parameters to stripe
the object across multiple data files on multiple disks or use volume manager
or I/O subsystem provided striping mechanisms.
- Use the KEEP pool: For reducing
scattered reads, many experts recommend implementing the KEEP pool. In the
Oracle Magazine
article "Advanced Tuning with Statspack", the author notes that that
small-table full-table scans should be placed in the KEEP pool to reduce
scattered read waits.
- Increase the data buffer cache size:
Obviously, the more data blocks we keep in RAM, the smaller the probability of
read waits.
Of the above solutions, SQL tuning is clearly the most
important in reducing physical read waits. In their landmark article "Diagnosing
Performance with Statspack",
Graham Wood and Connie Dialeris explain how to use Statspack to collect and
analyze high-resource SQL statements. The
stats$sqltext table keeps a record of historic
SQL, and it is easy to extract the SQL that was executing at the time of the
read waits. You can then gather the execution plans for the SQL statements and
verify they are using an optimal execution plan.
Remember, one characteristic of suboptimal SQL
execution is an unnecessary large-table full-table scan. For example, if you
query only returns 10 rows, it would not be optimal to be performing a
full-table scan on a 100 block table.
Now that we see the solutions, let's explore how we
get the data we need to fix the causes of the physical read waits.
Collecting Real-Time Wait Events
This article should not be taken as a comprehensive
approach to Oracle tuning, but it does provide tremendous insight into the
source of some disk I/O waits. Given that the
v$ views are
accumulators, and we can only see the sum the total number of waits since the
instance started, we must take a novel approach in order to capture the specific
objects that are associated with the waits.
We can do so by using the
v$session_wait view.
As disk read waits occur within the Oracle Database, they appear in the
v$session_wait view
for a very brief period of time. Because of the transient appearance of read
waits, it is impossible to catch all of the run-time waits. However, it is
possible to take a frequent sample of the
v$session_wait view and catch a representative
sample of the system-waits details at the exact moment that the events occur.
The exciting thing about the
v$session_wait view
is that we can capture the exact time the wait occurred, and the file and block
number that was being waited upon. When we have the file and block number, it's
possible to determine the exact table or index where the wait occurred.
We need to start by defining a table to hold the
information from the v$session_wait
view. Listing 1 captures the salient columns within the
v$session_wait view,
including the event name, the wait time, the seconds in wait, and the
all-important columns P1 and P2, where P1 is the file ID, P2 is the block number
of the event that is being waited upon.
Now that we've defined a table to hold the information
from v$session_wait,
the next step is to write to INSERT statement that will capture the wait events
as they occur. Please note that because of the transient nature of Oracle waits,
on many occasions this INSERT statement will return no rows into the table. For
the purpose of the simple example, we'll create this INSERT statement and then
place it with a crontab file on our UNIX server so that it runs every minute.
The simple script in Listing 2 should provide a brief representative sample of
waits every 60 seconds.
Next, we must place this INSERT statement inside a
script so that we can execute it from our cron (or using the AT command if you
are on MS-Windows; see Listing 3).
Finally, here is the crontab entry on the UNIX server
that will invoke the script every 60 seconds. That should be everything we need
to do in order to begin collecting detailed information on run-time I/O waits:
# ************************************************************
# Run 60-second check for run-time waits
# ************************************************************
* * * * * /opt/oracle/oracheck/get_waits.ksh mysid > /tmp/wt.lst
After allowing the script run for several days, we
should have a sufficient number of rows so that we can begin analyzing our
run-time wait data. As we've noted from the
v$session_wait view, it's very easy to display the
tablespace names and the exact block names for each and every wait. Listing 4
shows the SQL to display the detail.
Here is the output from this script; we can see the
exact time and block IDs when a physical I/O wait occurred:
System Wait File Block
Date Event ID ID
-------------------- ------------------------------ ----- -------------
23/01/2003 17:40:02 db file sequential read 6 300,929
23/01/2003 18:00:03 db file sequential read 8 35,936
23/01/2003 21:04:02 db file sequential read 3 65,162
23/01/2003 21:08:02 db file sequential read 6 23,031
23/01/2003 21:09:01 db file sequential read 5 40,585
23/01/2003 21:10:01 db file sequential read 6 512,663
23/01/2003 21:11:02 db file sequential read 5 26,609
23/01/2003 21:12:01 db file sequential read 5 40,584
Next, we can easily roll-up the number of waits,
organized by the type of wait and the hour of the day (see Listing 5). This is a
very important part of the wait analysis because it will reveal those times when
I/O tuning is required.
Below is the output from this script. Note that we
have summed the real-time I/O waits by date and hour of the day, which can give
us great insight into I/O processing times when the database is experiencing an
I/O bottleneck. From this output we see that this system experiences a
sequential I/O bottleneck each evening between 9:00PM and 10:00 PM:
Wait Wait
Date Hr. Event Count
-------------------- ------------------------------ -----
23-jan-2003 17 db file sequential read 1
23-jan-2003 18 db file sequential read 1
23-jan-2003 21 db file sequential read 53
23-jan-2003 22 db file sequential read 8
23-jan-2003 23 db file sequential read 7
24-jan-2003 00 db file sequential read 1
24-jan-2003 03 db file sequential read 1
24-jan-2003 05 db file sequential read 1
24-jan-2003 09 db file sequential read 4
24-jan-2003 11 db file sequential read 2
24-jan-2003 13 db file scattered read 1
24-jan-2003 13 db file sequential read 2
24-jan-2003 14 db file sequential read 2
24-jan-2003 17 db file sequential read 1
24-jan-2003 21 db file sequential read 75
Tracking I/O Waits on Specific Tables and Indexes
It should be clear that we still must be able to
translate the file number and block number into a specific table or index name.
We can do that by using the dba_extents
view to determine the start block and end block for every extent in every table.
Using dba_extents
to identify the object and its data block boundaries, it becomes a trivial
matter to read through our new table and identify those specific objects
experiencing read waits or buffer busy waits. Now we add the segment name by
joining into our dba_extents
view (see Listing 6).
Here is the output from this script. Here we see all
of the segments that have experienced more than 10 disk-read wait events:
Wait Segment Segment Wait
Event Name Type Count
---------- ----------------------------------- ---------- ------------
SEQ_READ SYSPRD.S_EVT_ACT_F51 INDEX 72
SEQ_READ SYSPRD.S_ACCNT_POSTN_M1 INDEX 41
SEQ_READ SYSPRD.S_ASSET_M3 INDEX 24
SEQ_READ SYSPRD.S_ASSET_M51 INDEX 19
SEQ_READ SYSPRD.S_COMM_REQ_U1 INDEX 11
Here we see the exact indexes that are experiencing
sequential read waits, and we now have an important clue for our SQL tuning or
object redistribution strategy.
To finish the analysis, we next want to see all "hot
blocks." We can do that by interrogating our
stats$real_time_waits
table, looking for any data blocks that have experienced multiple waits (see
Listing 7). Here we see each segment, the exact
block where the wait occurred, and the number of wait events:
Multiple
Block
Wait Segment Segment Block Wait
Event Name Type Number Count
---------- ------------------------------ ---------- ---------- --------
SEQ_READ SYSPRD.S_EVT_ACT_F51 INDEX 205,680 7
SEQ_READ SYSPRD.S_EVT_ACT TABLE 401,481 5
SEQ_READ SYSPRD.S_EVT_ACT_F51 INDEX 471,767 5
SEQ_READ SYSPRD.S_EVT_ACT TABLE 3,056 4
SEQ_READ SYSPRD.S_EVT_ACT_F51 INDEX 496,315 4
SEQ_READ SYSPRD.S_DOC_ORDER_U1 INDEX 35,337 3
This report is critical because it identifies those data blocks that have
experienced multiple block waits. We can then go to each data block and see the
contention on a segment header.
Trend-Base Event Wait Analysis
When we have the detailed event waits data, it is
trivial to roll-up the data and create trend reports. The SQL in Listing 8
produces an hourly average of sequential read waits.
It is important to note that every database will have
these "signatures," which are typically caused by regularly scheduled
processing. When the signatures are identified, we must use Statspack to extract
the SQL and ensure that it is properly optimized.
If the read waits persist, the next step is to
gerrymander the schedule to execute the colliding SQL at different times. If you
do not have the I/O bandwidth to run your full workload all at once, move some
of the workload to different time window.
To display trend by day, a similar query may be run
that will average the number of sequential read waits by day of the week (see
Listing 9).
We can then quickly plot the I/O wait data (I used the
Microsoft Excel chart wizard in this case) and see repeating trends within our
database (see Figure 1). Best of
all, we have the detailed information in our
stats$real_time_waits
view so that we can investigate the exact table or index that is experiencing
the real-time wait. If we do that in conjunction with Statspack, we may also
collect the SQL in the stats$sql_summary
table and see the SQL that is precipitating the disk wait events.
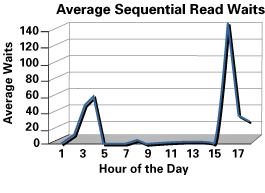
|
| Figure 1: Plotting real-time waits
averages by hour of the day |
In this case, we see a high number of real-time 'db
file sequential read waits' waits from 2:00 AM - 3:00 AM, and another spike between
9:00 PM and midnight each night. We can use this information to go to Statspack
and extract the SQL that was running during this period.
Using the supplied script, we can also average to read
waits by day of the week (see Figure 2).
Here we see a clear increase in scattered read waits every Tuesday and Thursday
and we can extract the SQL during these periods.

|
| Figure 2: Plotting real-time waits
averages by day of the week |
Normally, this insight would not be very useful
because we could not see the source of the waits. (Of course, if we are using
Oracle9i Rel 2, we can use the
v$segment_statistics view to see some of this
information if we set the statistics_level
parameter to a value of 7 or higher.)
Regardless, because we have the original wait detail
data stored in stats$real_time_waits,
we can easily see the offending objects (see Listing 10).
We can now drill-in and see those specific table and
indexes that were experiencing the sequential read waits.
Block
Segment Segment Wait
Date Hr. Name Type Count
-------------------- ------------------------------ ---------- --------
23-jan-2003 21 SYSPRD.S_COMM_REQ_SRC_U1 INDEX 23
23-jan-2003 21 SYSPRD.S_EVT_ACT TABLE 44
23-jan-2003 21 SYSPRD.S_EVT_ACT_F51 INDEX 16
23-jan-2003 22 SYSPRD.S_EVT_ACT TABLE 32
It is important that we know the specific object that
experiences the physical read wait, because we may wish to distribute the object
over additional disk spindles.
Search and Tune
Using a real-time wait sampling method, you can easily
capture the details about the objects that experience physical read waits. When
they're identified, we can then use Statspack to locate the offensive SQL and
begin the tuning. The tuning of physical read waits is SQL tuning, object
striping across multiple disks, employing the KEEP pool for small objects,
re-scheduling the SQL to relieve the contention or increasing the data buffer
cache size.
Special thanks are in order to Graham Wood, the
Oracle Corporation super-guru and creator of Statspack. Graham was instrumental
in ensuring that this article was complete, accurate and useful.
Donald K. Burleson is one of the world's most widely-read Oracle database experts. He has written
30 books,
published more than 100 articles in national magazines, and serves as
editor-in-chief of Oracle Internals,
a leading Oracle database journal. Burleson's latest book is
Oracle Tuning: The Definitive Reference
by Rampant Techpress.
 |
|
Get the Complete
Oracle SQL Tuning Information
The landmark book
"Advanced Oracle
SQL Tuning The Definitive Reference" is
filled with valuable information on Oracle SQL Tuning.
This book includes scripts and tools to hypercharge Oracle 11g
performance and you can
buy it
for 30% off directly from the publisher.
|
|
